I am using torchtian with FSDP2 + PP(1F1B) to train llama3-8b, however, I found that as the micro batch count increasing, the GPU memory usage will increase rapidly (from 42.27GB to 64.57GB) on the last pp stage. That’s a bit strange, AFAK, the GPU memory should not increase too much though use larger micro batch count (After all, we need to use larger micro batch count to decrease the bubble rate).
Here is my experiment settings and results:
using 4 GPUs and DP2-PP2 to train llama3-8b (pruned, 16 layers)
pytorch version: 2.9.0.dev20250725+cu126
torchtitan version: v0.1.0
command:
LOG_RANK=2 NGPU=4 CONFIG_FILE=./torchtitan/models/llama3/train_configs/llama3_8b.toml ./run_train.sh --metrics.log_freq 1 --training.seq_len 4096 --training.steps 1000 --parallelism.data_parallel_shard_degree 2 --activation_checkpoint.mode full --parallelism.pipeline_parallel_degree 2 --training.local_batch_size 16
memory: torch max reserved memory
rank0 is pp stage0, rank2 is pp stage1 (last stage)
| micro batch count | memory (GB) on rank0 | memory (GB) on rank2 |
|---|---|---|
| 2 | 35.75 | 40.30 |
| 4 | 35.80 | 42.27 |
| 8 | 35.94 | 48.27 |
| 16 | 36.20 | 65.47 |
Also, I dumped the memory snapshot of last PP stage and found that the output (shape: 4096 * 128256) of LM head in each micro batch keeps alive during the step period
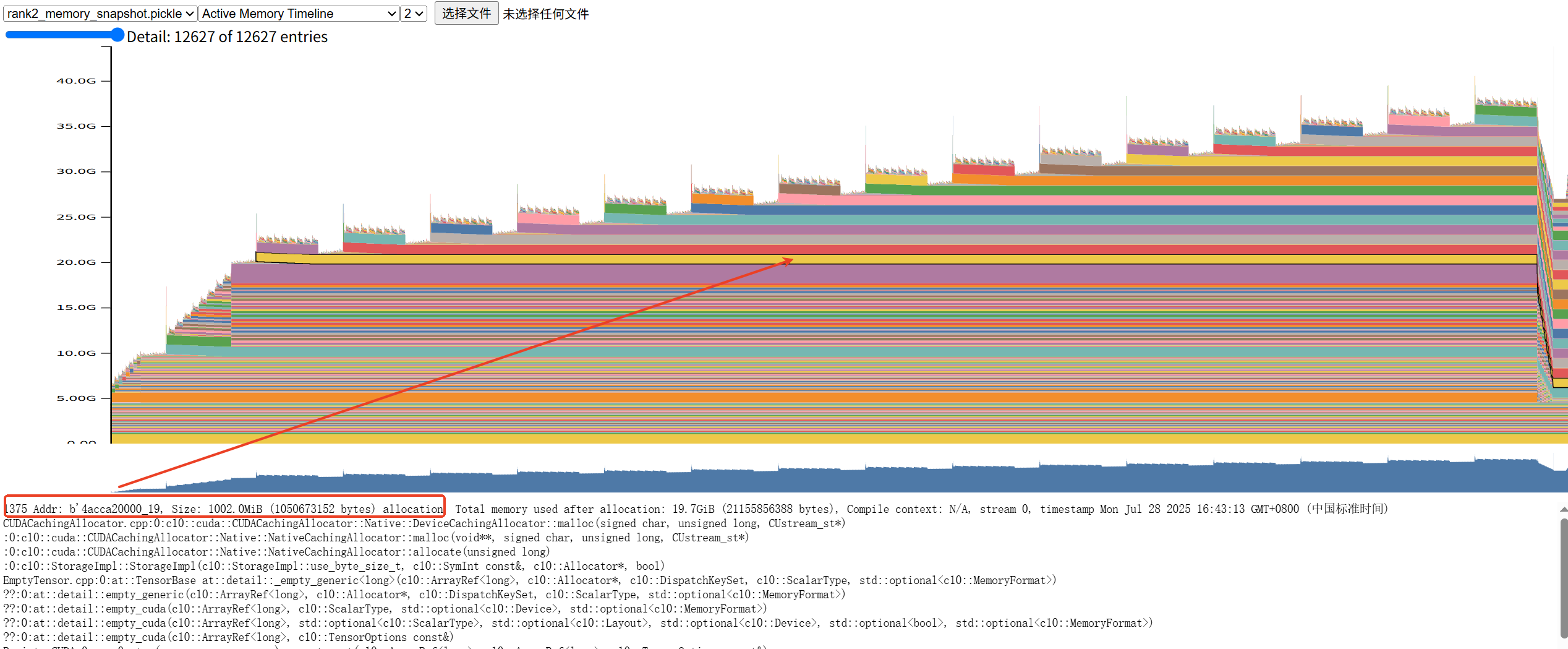
I checked the implementation of pipeline parallelism and found that PyTorch will caching chunk outputs after forward_maybe_with_no_sync in forward_one_chunk function, this may explains the GPU memory behavior of the above, but my question is: Do we really need to cache the chunk output during training, perhaps we only need to cache output during evaluation or inference ? Or let the users choose whether enable caching outputs or not.
After I tried to disable caching outputs with some modifications like below, the GPU memory usage looks normal:
class _PipelineStageBase(ABC):
def __init__(self, ...):
...
# use `requires_merge_outputs` as a switch
self.requires_merge_outputs: bool = True
def forward_one_chunk(self, ...):
...
output = self.forward_maybe_with_nosync(*composite_args, **composite_kwargs)
if self.is_last and self.requires_merge_outputs:
self.output_chunks.append(output)
...
class PipelineScheduleSingle(_PipelineSchedule):
def step(self, *args, target=None, losses: Optional[list] = None, **kwargs):
...
if self._stage.is_last and self._stage.requires_merge_outputs:
return self._merge_outputs(self._stage.output_chunks)
else:
return None
# expose to the user
def set_requires_merge_outputs(self, requires_merge_outputs: bool):
self._stage.requires_merge_outputs = requires_merge_outputs
Now the GPU memory usage more stable
| micro batch count | memory (GB) on rank0 | memory (GB) on rank2 |
|---|---|---|
| 2 | 35.75 | 40.30 |
| 4 | 35.80 | 40.38 |
| 8 | 35.94 | 40.41 |
| 16 | 36.20 | 41.64 |