Hello everyone, I am a PyTorch beginner and would like to get help applying the conv2d-LSTM model.
I have a 2D image (1 channel x Time x Frequency) that contains time and frequency information.
I’d like to extract features automatically using conv2D and then LSTM model because 2D image contains time information
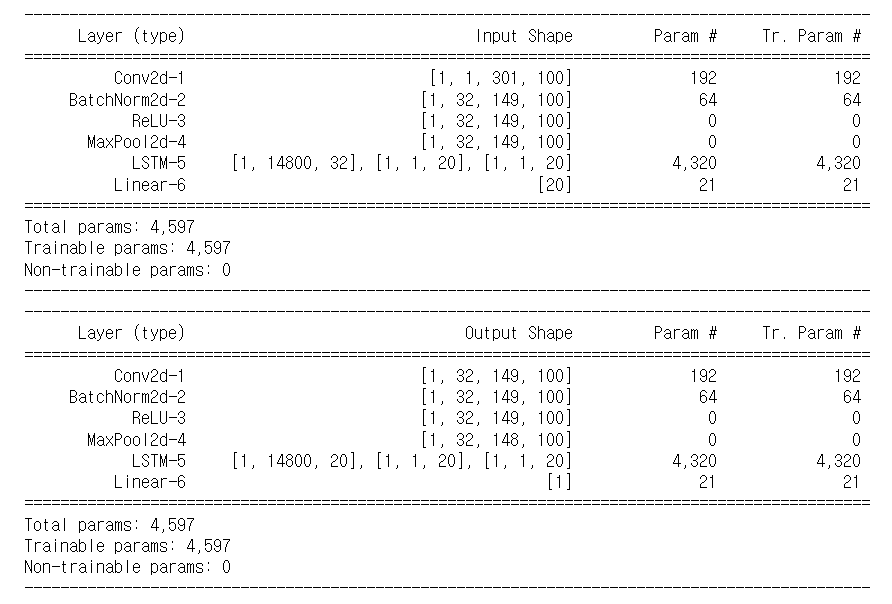
According to PyTorch documents, the output shape of conv2D is (Batch size, Channel out, Height out, Width out) and the input shape of LSTM is (Batch size, sequence length, input size). From that, I thought before input features of the LSTM network there need to reshape the output features of conv2D.
I expected the cnn-lstm model to perform well because it could learn the characteristics and time information of the image, but it did not get the expected performance.
My question is when I insert data into the LSTM model, is there any idea that LSTM learns the data by each row without flattening? Should I always flatten the 2D output?
My networks code and input/output shape are as follows. (I maintained the width size in the conv layer to preserve time information.)
Thanks a lot
class CNN_LSTM(nn.Module):
def __init__(self, paramArr1, paramArr2):
super(CNN_LSTM, self).__init__()
self.input_dim = paramArr2[0]
self.hidden_dim = paramArr2[1]
self.n_layers = paramArr2[2]
self.batch_size = paramArr2[3]
self.conv = nn.Sequential(
nn.Conv2d(1, out_channels=paramArr1[0],
kernel_size=(paramArr1[1],1),
stride=(paramArr1[2],1)),
nn.BatchNorm2d(paramArr1[0]),
nn.ReLU(),
nn.MaxPool2d(kernel_size = (paramArr1[3],1),stride=(paramArr1[4],1))
)
self.lstm = nn.LSTM(input_size = paramArr2[0],
hidden_size=paramArr2[1],
num_layers=paramArr2[2],
batch_first=True)
self.linear = nn.Linear(in_features=paramArr2[1], out_features=1)
def reset_hidden_state(self):
self.hidden = (
torch.zeros(self.n_layers, self.batch_size, self.hidden_dim).to(device),
torch.zeros(self.n_layers, self.batch_size, self.hidden_dim).to(device)
)
def forward(self, x):
x = self.conv(x)
x = x.view(x.size(0), x.size(1),-1)
x = x.permute(0,2,1)
out, (hn, cn) = self.lstm(x, self.hidden)
out = out.squeeze()[-1, :]
out = self.linear(out)
return out