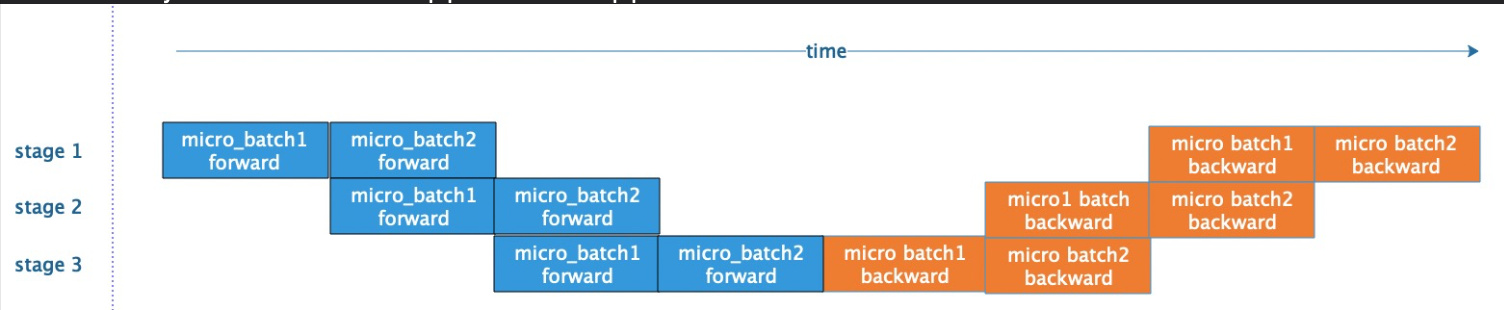
I notice that in https://github.com/pytorch/examples/tree/master/distributed/rpc/pipeline, every input batch is divided into micro-batches. This sorta likes GPipe method. But the backward pass is not parallelized, which contradicts GPipe. I wonder if there is any papers or references that can explain what pipeline algorithm are being used.
If so, is there any chances to enhance it? Makes it more like this chart below.
Do you need single-machine multi-GPU pipeline parallel or multi-machine pipeline parallel?
If it is within a single machine, it is possible to parallelize backward as well. Check this project torchgpipe. It inserts phony dependencies between stages of different micro batches.
If it’s multi-machine pipeline parallel, then you will need RPC. As of today distributed autograd cannot parallelize backward, because the smart mode has not been implemented yet. To get around this, you can still use RPC and RRef, but cannot use distributed autograd and will need to manually stitch together local autograd.
Another possibility (not 100% sure if this would work) is to create one distributed autograd context per micro batch, and manually call __enter__ and __exit__ on distributed autograd context. As a result, the gradients for different microbatches will be stored in different contexts, and hence you will need to call dist_optimizer.step(ctx_id) multiple times to apply the gradients.
Things will become a lot easier when we add smart mode distributed autograd.