Hello!
I am trying to quantize the model to 4bit. My torch version is 1.7.1
I have changed the quant_min and quant_max in qconfig.py, fake_quantize.py, and observer.py (like below)
if backend == 'fbgemm':
qconfig = QConfig(activation=FakeQuantize.with_args(observer=MovingAverageMinMaxObserver,
quant_min=0,
quant_max=15,
reduce_range=True),
weight=default_per_channel_weight_fake_quant)
default_per_channel_weight_fake_quant = FakeQuantize.with_args(observer=MovingAveragePerChannelMinMaxObserver,
quant_min=-8,
quant_max=7,
dtype=torch.qint8,
qscheme=torch.per_channel_symmetric,
reduce_range=False,
ch_axis=0)
if self.dtype == torch.qint8:
if self.reduce_range:
quant_min, quant_max = -4, 3
else:
quant_min, quant_max = -8, 7
else:
if self.reduce_range:
quant_min, quant_max = 0, 7
else:
quant_min, quant_max = 0, 15
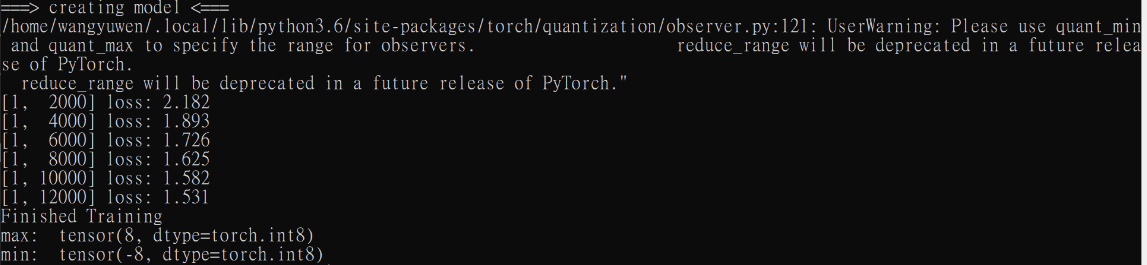
I have checked that the range of weights in fake_quantize is correct (In fake_quantize I quantize the weight to check if it is correct or not)
But I get the max value of weights is 8 when I inference the model. It should be 7.
for layer in model.modules():
if isinstance(layer, nn.quantized.Conv2d):
w, b = layer._weight_bias()
print(w.int_repr().max())
This is the result of the screenshot.

Is there anything else that needs to be chnaged?
Thanks!