The tutorial address is as followed:
https://pytorch.org/tutorials/beginner/audio_preprocessing_tutorial.html#adding-background-noise
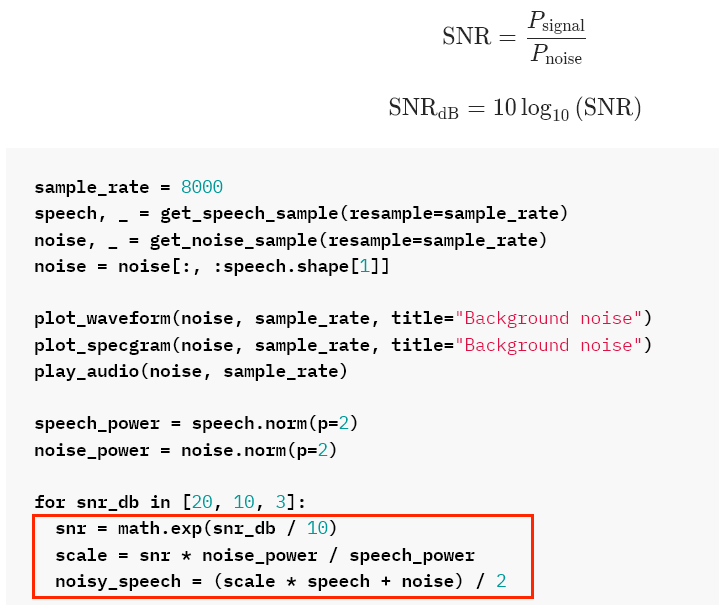
The part confuses me most is in this picture:
My question is: how does this code work? what’s the principle of mathmatics and derivative process behind it?
Any reference is appreciated.
According to Wikipedia

Given a desired SNR value, you just need to scale your speech signal so that the output of the above formula is equal to the desired one.
Thanks, I understand now. But why divided by 2 at last?
It’s just a practical operation to avoid value overflow. If the dtype of the waveform is float, the value range must be [-1, 1]. I would recommend dividing the noisy speech signal by the max absolute value, which can guarantee such range.