Hello, guys
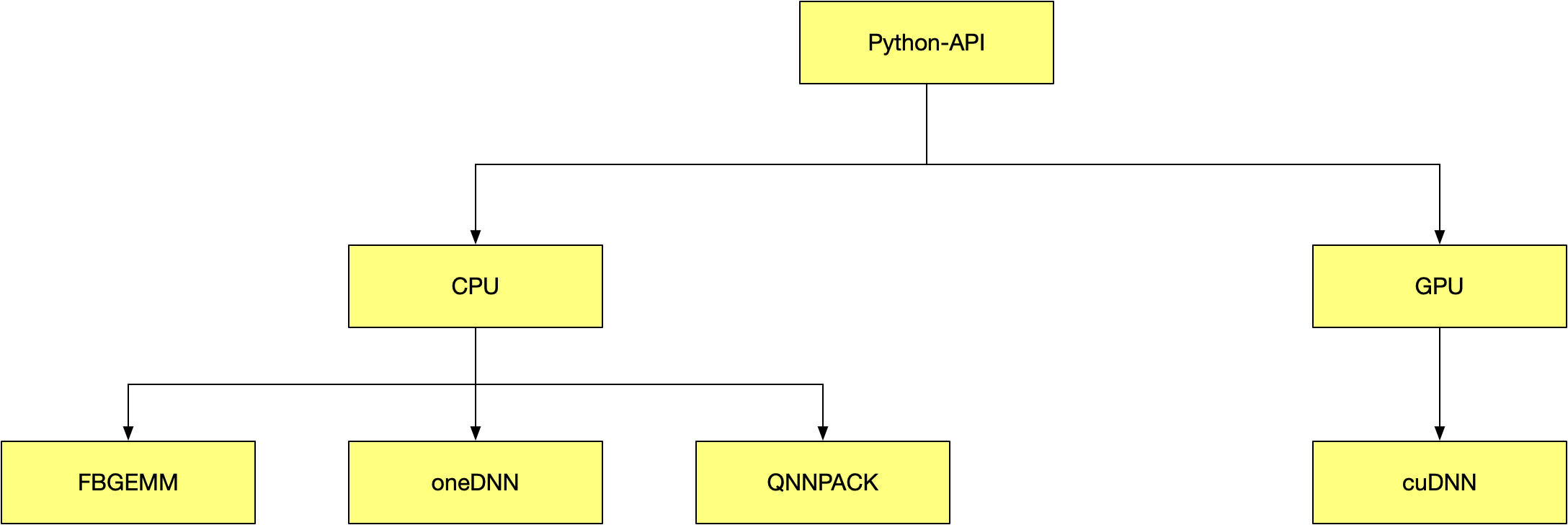
recently I learned the source code of pytorch, I quantized my cnn layer and see the backend of it’s implementation. My system is Mac M1, so I can’t use GPU(CUDA), so I can only use CPU. From director y “ATen/native/quantized/cpu” I can see a lot of quantized layers like “qconv” and so on.
In the file “qconv.cpp” I can see there are three macro: USE_FBGEM.
MUSE_PYTORCH_QNNPACK. AT_MKLDNN_ENABLED. Does this means that I can use anyone of these three? In another word, pytorch support three kind of quantization implementation in cpu and which one to use depends on what macro I defined ?