I want to train a model where the loss has been increasing before the last modification. The loss does not converge after the modification.
that is my model:
class u_seta(nn.Module):
def __init__(self, input_dim, output_dim):
super().__init__()
self.block = nn.Sequential(
nn.Linear(input_dim, 256),
nn.PReLU(),
nn.Linear(256, 512),
nn.PReLU(),
nn.Linear(512,256),
nn.PReLU(),
nn.Linear(256, output_dim)
)
def forward(self, x):
out = self.block(x)
return out
I am using Adam Optimizer:
u_setaNet = utils.KRU_utils.u_seta(75,72).to(device)
optimizer = torch.optim.Adam(u_setaNet.parameters(),lr=0000000000.1)
Training sequence
for now_step in range(n+1):
if(now_step==0):
q_i_est = data_3D_pose.clone().to(device)
X_est = utils.KRU_utils.pose_to_3d(q_i_est,data_3D).to(device)
x_est = utils.KRU_utils.joint3d_to_2d(X_est,data_3D).to(device)
Loss = utils.KRU_utils.LossF(x_est,data_2D_keypoint).to(device)
Loss = Loss.sum(dim=1)
X_est = torch.autograd.grad(outputs=Loss,inputs=X_est,grad_outputs=torch.ones_like(Loss))[0]
X_est = X_est.reshape(X_est.shape[0],-1).to(device)
Loss = Loss.detach()
else:
q_i_est = q_i_est.detach()
X_est.requires_grad = True
q_i_est_alter = u_setaNet(X_est)
q_i_est = q_i_est + q_i_est_alter
X_est = utils.KRU_utils.pose_to_3d(q_i_est,data_3D).to(device)
x_est = utils.KRU_utils.joint3d_to_2d(X_est,data_3D).to(device)
Loss = utils.KRU_utils.LossF(x_est,data_2D_keypoint).to(device)
Loss = Loss.sum(dim=1)
optimizer.zero_grad()
X_est = torch.autograd.grad(outputs=Loss,inputs=X_est,grad_outputs=torch.ones_like(Loss))[0]
optimizer.step()
X_est = X_est.reshape(X_est.shape[0],-1).to(device)
Loss = Loss.detach()
The loss function is:
def LossF(joint2d,data_2D_keypoint):
Loss = joint2d[:,:,0:2] - data_2D_keypoint[:,:,0:2]
Loss = torch.sqrt(Loss[:,:,0]** 2 + Loss[:,:,1]** 2)
Loss = (Loss*data_2D_keypoint[:,:,2])
return Loss
A series of transformations are performed after the network output, will this cause anomalies in the training?
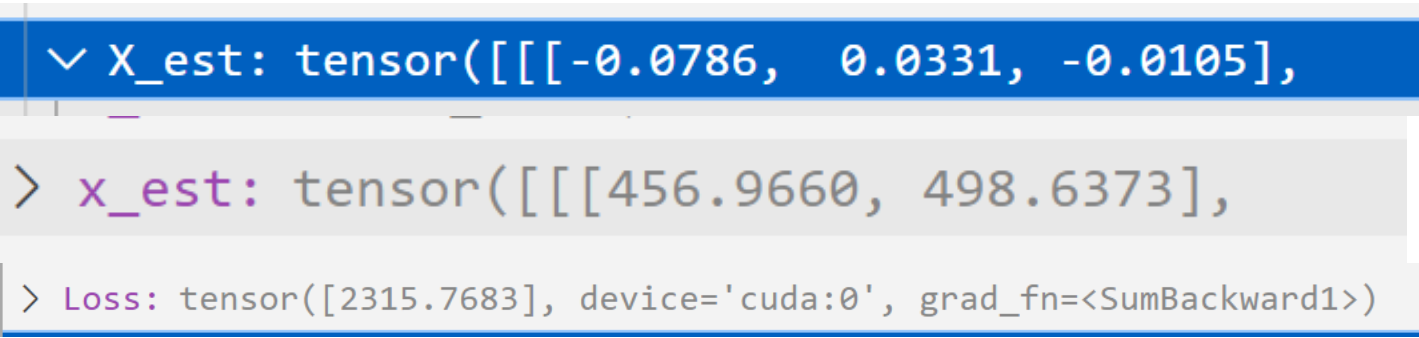
How should I modify it? please help me to find the problem ![]()