When I want to use kl divergence, I find there are some different and strange use cases.
The formulation of KL divergence is
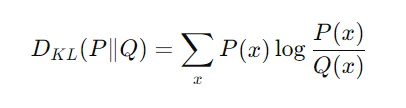
and the P should be the target distribution, and Q is the input distribution.
According to the API doc,

I assume the first args `input’ should be Q, and the second args target should be P.
However, I asked GPT, it gave me the answer below

It seems reversed. I also see some implementations that used the target distribution(P)
as the first args. This confuses me.
Why does the first args need to be used with the .log() function? If this is necessary, why don’t implement the .log inside the function `kl_div’?
Whether the first or second args should be the true target distribution (P)?
Moreover, I also see there is an argument named log_target. I still do not understand why we need this argument.
Appreciate any reply!