While implementing neural models by myself without aid of pytorch module, I become curious about how backpropagation is implemented in pytorch.
In pytorch, explicit implementation of backward function is not needed unlike forward function.
However, I can’t understand how pytorch automatically understands the structure of a net so that backpropagation can be carried out.
For example, let’s see the picture below.
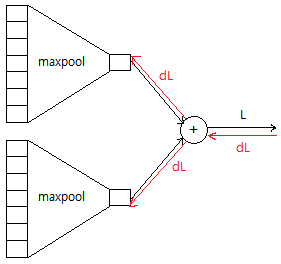
It can be implemented like this.
maxpool1 = nn.MaxPool2d((7, 1), stride=(1, 1))
maxpool2 = nn.MaxPool2d((7, 1), stride=(1, 1))
m1 = maxpool1.forward(x1)
m2 = maxpool2.forward(x2)
c = m1 + m2
pytorch must know that there is an add layer to convey dL to the maxpool Layer, but c is calculated by just adding two, without a certain layer class.
(Like this)
add = nn.some_add_layer(2) # 2 inputs
c = add.forward(m1, m2)
Then how does pytorch know that there is an add layer?
Pytorch builds a computational Graph for everything you do from your Data to finding out loss.Typical Pytorch training looks like below -
for epoch in range(num_epochs):
for data , labels in train_loader:
## Whatever you do from here to calculating loss Pytorch will build computational
Graph for it.
##loss.backward()
##Optimizer.step()
##Optimizer.zero_grad.
Now to be specific , You dont need to use only nn Modules to have this computational graph , You can do simple addition,matrix multiply or whatever and pytorch will still be able to build graph for it and when you call loss.backward() it will be able to do backpropagation.
It seems that every computational process is stored in each tensor variable as a “grad_fn” attribute. Am I right?
Yes , Unless you do some computation inside torch.no_grad() pytorch will keep track of your each steps and associate a way to go backward and finally will build a computational graph .