While doing self attention at the encoder layer I get the following attention_weights as my output.
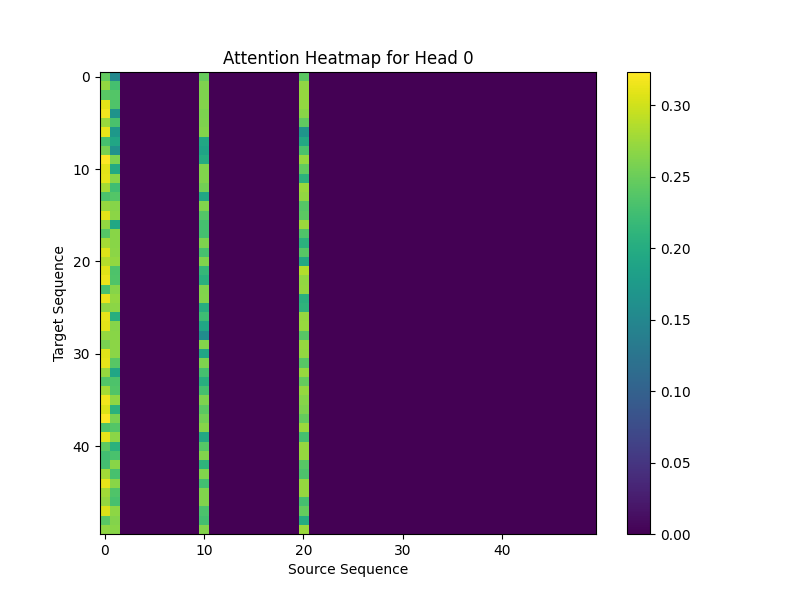
Its clear that key_padding_mask masks the attention where the padding’s are given but why it’s only in one axis, I was expecting the heat map to have zeroes for the masked regions in the y direction as well. can you help me solve this.
this is how my key_padding_mask looks like
tensor([[False, False, True, True, True, True, True, True, True, True, False, True, True, True, True, True, True, True, True, True, False, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True]], device='cuda:0')
2023-10-03T22:00:00Z