Dear Community,
I’m trying to port this Encoder network l2b/encoder.py at master · haebeom-lee/l2b · GitHub and I’m getting confused. Could someone please give me some guidance on the following?
1 Should I have backward propagation for this network? Its loss is combined with the loss from the ‘main’ Model-Agnostic Meta-Learning network and optimized by the optimizer. (Tensorflow’s optimizer just takes the loss, not the parameters, so I’m not sure if this Encoder network’s parameters should be part of my argument when I initialize my torch.optim.Adam)
2 Should I make this network by the ‘conventional’ method (inheriting from nn.Module) or the dictionary (dict[str, torch.Tensor]) method? I tried the former but found myself setting up a bunch of sub-networks and nn.LazyLinear which I don’t think is correct.
The Tensorflow implementation is using functions like dense() defined in l2b/layers.py at master · haebeom-lee/l2b · GitHub is creating tensor variables, so it’s like using the dictionary method and doing the torch.nn.Functional.layer to manually calculate stuff rather than using torch.nn.that_same_layer’s forward method? I’m baffled! ![]()
Thanks so much!
P.S. I read the paper and, the Encoder is illustrated as:
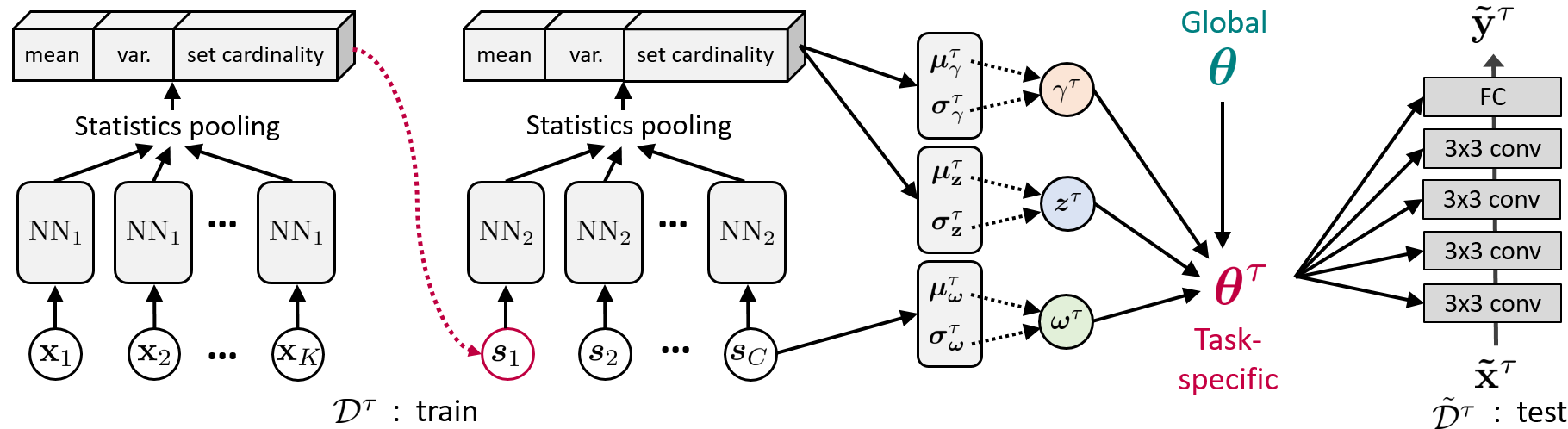
Honestly, this hasn’t been much help to me. What I could make out from the paper is:
info 1 The 3x3 Cones and FC is the main network (model-agnostic meta-learning, which is using the dict[str, torch.Tensor] method–probably because it gets backward propagation twice?)
info 2 There are two layers of these NNs, which I think can be nn.Module? We get mean, variance, and cardinality from them, repeat the process, and send the statistics to the red, green, blue circles, which are the ‘balancing’ variables to improve MAML’s performance. (It seems like this network is just doing some complicated things to get basic statistics like mean and variance?–I can’t put my finger on it!)
info 3 The x is a input. There are K of them in each class, and there are C classes total.
Source: l2b/images/encoder.png at master · haebeom-lee/l2b · GitHub
{kind=link}