try:
img = self.loader(os.path.join(self.root, path))
except Exception as e:
index = index - 1 if index > 0 else index + 1
return self.__getitem__(index)
Is there a better way to solve this, i.e. modifying the code of dataloader to load another Image when exception or write a new loader.
or does it work if I simply return None when caught an exception?
you can look at the default_collate function if it handles None or not.
Or you can give a custom collate function to your DataLoader which will handle None:
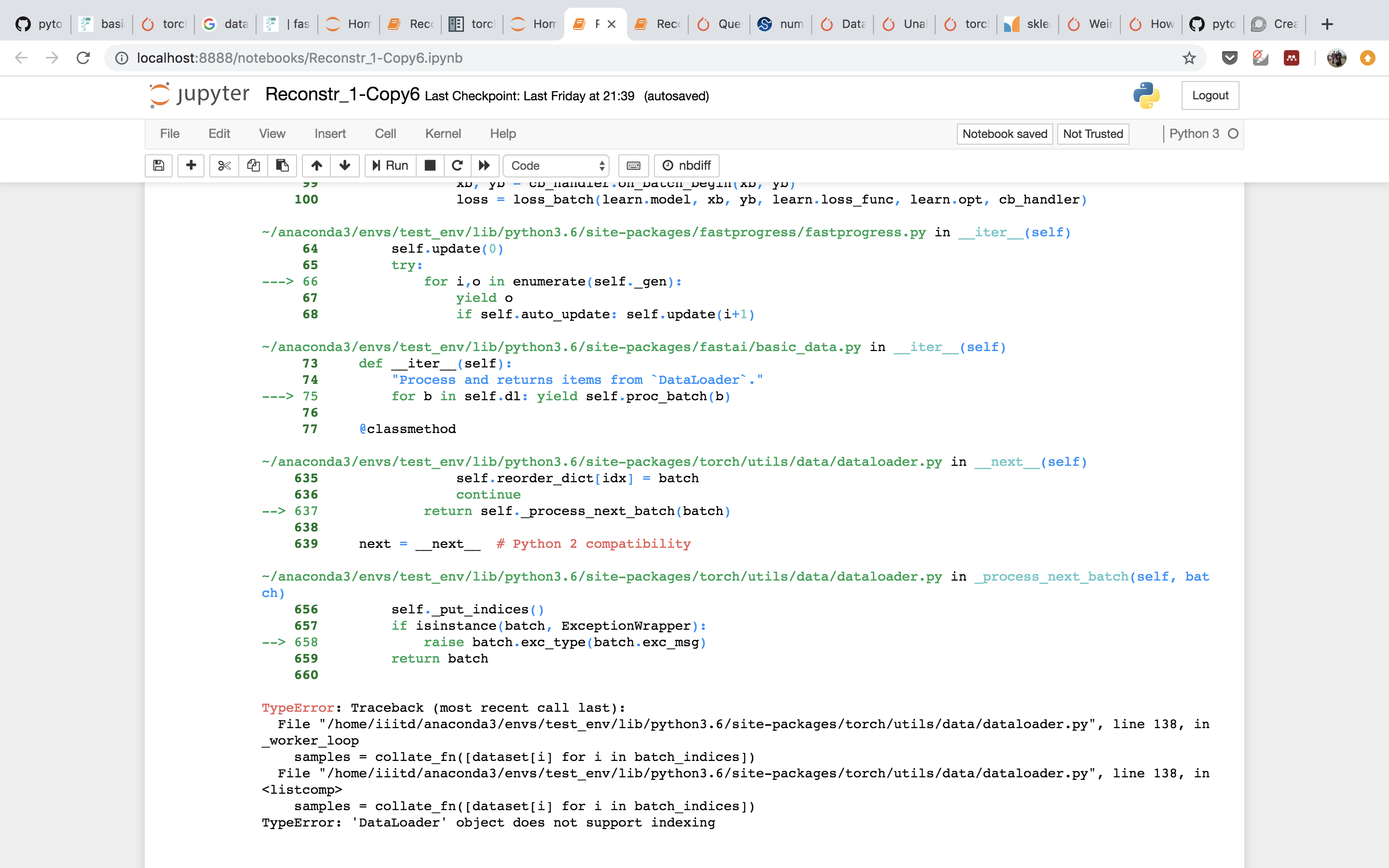
The DataLoader doesn’t support recovery from errors in datasets because it would be too complex to add and keep the guarantee that it will always return the batches in the exact same order, as the sampler generated. It’s not even clear what’s the behaviour that user expects (some people might want to be notified about the error, others don’t).
thanks @smth@apaszke, that really makes me have deeper comprehension of dataloader.
At first I try:
def my_loader(path):
try:
return Image.open(path).convert('RGB')
except Exception as e:
print e
def my_collate(batch):
"Puts each data field into a tensor with outer dimension batch size"
batch = filter (lambda x:x is not None, batch)
return default_collate(batch)
dataset= ImageFolder('/home/x/train/',
transform=transforms.Compose([transforms.ToTensor()]),
loader = my_loader)
dataloader=t.utils.data.DataLoader(dataset,4,True,collate_fn=my_collate)
it raise exception, because transforms in dataset can’t handle None
so then I try this:
def my_collate(batch):
batch = filter (lambda x:x is not None, batch)
return default_collate(batch)
class MyImageFolder(ImageFolder):
__init__ = ImageFolder.__init__
def __getitem__(self, index):
try:
return super(MyImageFolder, self).__getitem__(index)
except Exception as e:
print e
dataset= MyImageFolder('/home/x/train/', transform = transforms.Compose([transforms.ToTensor()..]) )
dataloader=t.utils.data.DataLoader(dataset, 4, True, collate_fn=my_collate)
not so pythonic, but it works.
and I think the best way maybe just cleaning the data.
I wrote a PyTorch library that allows you to do exactly this - drop samples, handle bad items, use Transforms as Filters (and more). Check out nonechucks.
Using nonechucks, your code would look something like this:
dataset= ImageFolder('/home/x/data/pre/train/',
transform=transforms.Compose([transforms.Scale(opt.image_size),
transforms.RandomCrop(opt.image_size) ,
transforms.ToTensor(),
transforms.Normalize([0.5]*3,[0.5]*3)
]))
import nonechucks as nc
dataset = nc.SafeDataset(dataset)
dataloader = nc.SafeDataLoader(dataset,opt.batch_size,True,num_workers=opt.workers)
# You can now use `dataloader` as though it was a regular DataLoader without
# having to worry about the bad samples!
Feel free to check out the documentation on the Github page!
This does not work if the batch size is 1, since default_collate will be called with an empty list in that case. The same thing could happen if the batch size is larger and all the data samples in the batch size are corrupt (highly unlikely though).
Is there a way to get this to work when the batch size is only 1?
I faced the same issue. my hot fix was to return a datapoint drawn randomly from the dataset.
so basically, catch the error and return a valid batch with a single datapoint.
It can happen in other cases where the batch_size > 1,but last batch has only 1 datapoint.