Which data format of the picture that ImageFolder can read? (pickle, JPG or PNG)
From the code (torchvision.datasets.folder.py), supported formats:
IMG_EXTENSIONS = [
'.jpg', '.JPG', '.jpeg', '.JPEG',
'.png', '.PNG', '.ppm', '.PPM', '.bmp', '.BMP',
]
Ok, I found the solution。

but, how to read labels of pictures
Thank you very much!
But how can I read lables?
The directory name is the class name I think, also from torchvision.datasets.folder.py
def find_classes(dir):
classes = [d for d in os.listdir(dir) if os.path.isdir(os.path.join(dir, d))]
classes.sort()
class_to_idx = {classes[i]: i for i in range(len(classes))}
return classes, class_to_idxThe labels are the sub-folders from the main directory. Say you have mnist images separated by digit like this:
main_dir/
0/
img1_digit0.jpg
img2_digit0.jpg
1/
img3_digit1.jpg
....
....
9/
...
Then you create an ImageFolder object.
from torchvision.datasets import ImageFolder
from torchvision.transforms import ToTensor
data = ImageFolder(root='main_dir', transform=ToTensor())
Note that you have the ToTensor() transform to convert from jpg to torch tensor.
Now the unique set of class labels is found easily, but this isn’t the class label for each individual image.
print(data.classes) # ['0','1',..'9']
And the images can be accessed by an integer index:
x,y = data[0] # x is the first image as PIL, y is that images class label
You can easily iterate through these images:
for i in range(len(data)):
x,y = data[i]
But for sampling like an iterator, I think you should use DataLoader class:
from torch.utils.data import DataLoader
loader = DataLoader(data)
for x, y in loader:
print(x) # image
print(y) # image label
Now, just FYI - I believe this will sample all the 0 images first, then all the 1 images, etc. To shuffle the images instead, you can either set shuffle=True in the DataLoader:
loader = DataLoader(data, shuffle=True)
Or, you can create an instance of the RandomSampler class found in torch.utils.data.sampler.py and pass that into the DataLoader as the sampler argument:
from torch.utils.data import RandomSampler
sampler = RandomSampler(data)
loader = DataLoader(data, sampler=sampler)
Also, note that if you want to read in data in a folder of a different type (e.g. numpy arrays), you can make your own function and pass it into the ImageFolder class in the loader argument. This function should take in a file path and return the loaded data.
import numpy as np
def my_numpy_loader(filename):
return np.load(filename)
data = ImageFolder(root='path/to/numpy/maindir/', loader=my_numpy_loader, transform=ToTensor())
The ToTensor() transform will do its job to convert the numpy array to a torch tensor. However, unfortunately it seems that all the other transforms (e.g. cropping, flipping, etc) only work on PIL images, so you’ll have to build your own transforms for that.
EDIT: As @apaszke notes, you can use the ToPILImage() transform to convert your array to PIL to use the transforms… I’d personally prefer transforms to work directly on torch tensors, but that’s just my opinion.
Example:
import numpy as np
def my_numpy_loader(filename):
return np.load(filename)
from torchvision.transforms import Compose, ToPILImage, ToTensor, ...
my_transform = Compose([ToPILImage(), ... typical transforms .., ToTensor()])
data = ImageFolder(root='path/to/numpy/maindir/',
loader=my_numpy_loader, transform=my_transform)
Here, you convert numpy -> pil image -> do some transforms -> convert back to torch tensor…
Speaking of formats, would it be possible to add secondary LSUN datasets to torchvision? ex. bird.
Was somewhat surprised they weren’t supported.
http://www.yf.io/p/lsun
"20 object categories"
http://tigress-web.princeton.edu/~fy/lsun/public/release/
submit an issue on https://github.com/pytorch/vision
Dose pytorch have any functions to read the images from pickle file?
@yichuan9527 why not use pickle.load? If you want to use it with ImageFolder just provide pickle.load as load function.
@Veril yes, if you think there’s a dataset that we don’t have but it would be useful, please open an issue in the vision repo.
@ncullen93 all the transforms work only on PIL images, but you can use ToPILImage() to convert a tensor back to a PIL image.
I noticed that ImageFolder can process following structure:
root/dog/xxx.png
root/dog/xxy.png
root/cat/123.png
root/cat/asd932_.png
My question is, can it process a deeper /nested folder structure? e.g.:
root/mammal/dog/xxx.png
root/mammal/cat/xxy.png
root/avian/pigeon/123.png
root/avian/crow/nsdf3.png
If yes, would the classes be “mammal, avian”, or would they be “dog, cat, pigeon, crow”?
Thanks!
it will return an empty dataset. because there is no pictures in folder mamma and avian.
You can just create softlink in linux, to make them in the same folder.
Also the source code of Imagefolder is really simple to read and modify, you can inherit it and make some modify. have a try.
like
class TrainImageFolder(ImageFolder):
def __getitem__(self, index):
filename = self.imgs[index]# 'avian/crow/nsdf3.png'
if filename.split('/')[0] =='avian': label = 0
### or
# if filename.split('/')[1] =='dog': label = 0
return super(TrainImageFolder, self).__getitem__(index)[0], label
Hello everyone! Does anyone know how can i merge two ImageFolder objects into one? If you can look at this issue i would really appreciate it:
You can use ConcatDataset documentation to merge different Dataset s into one.
However, in your other question you would like to save the randomly transformed images, right?
You could just iterate your Dataset and save the images using PIL. It’s not really common though, since you augment the dataset on the fly without saving it usually.
Thank you for your reply ! I just tried implementing the code i saw in the documentation you presented but i ran into an error. Here is a screenshot of my code :
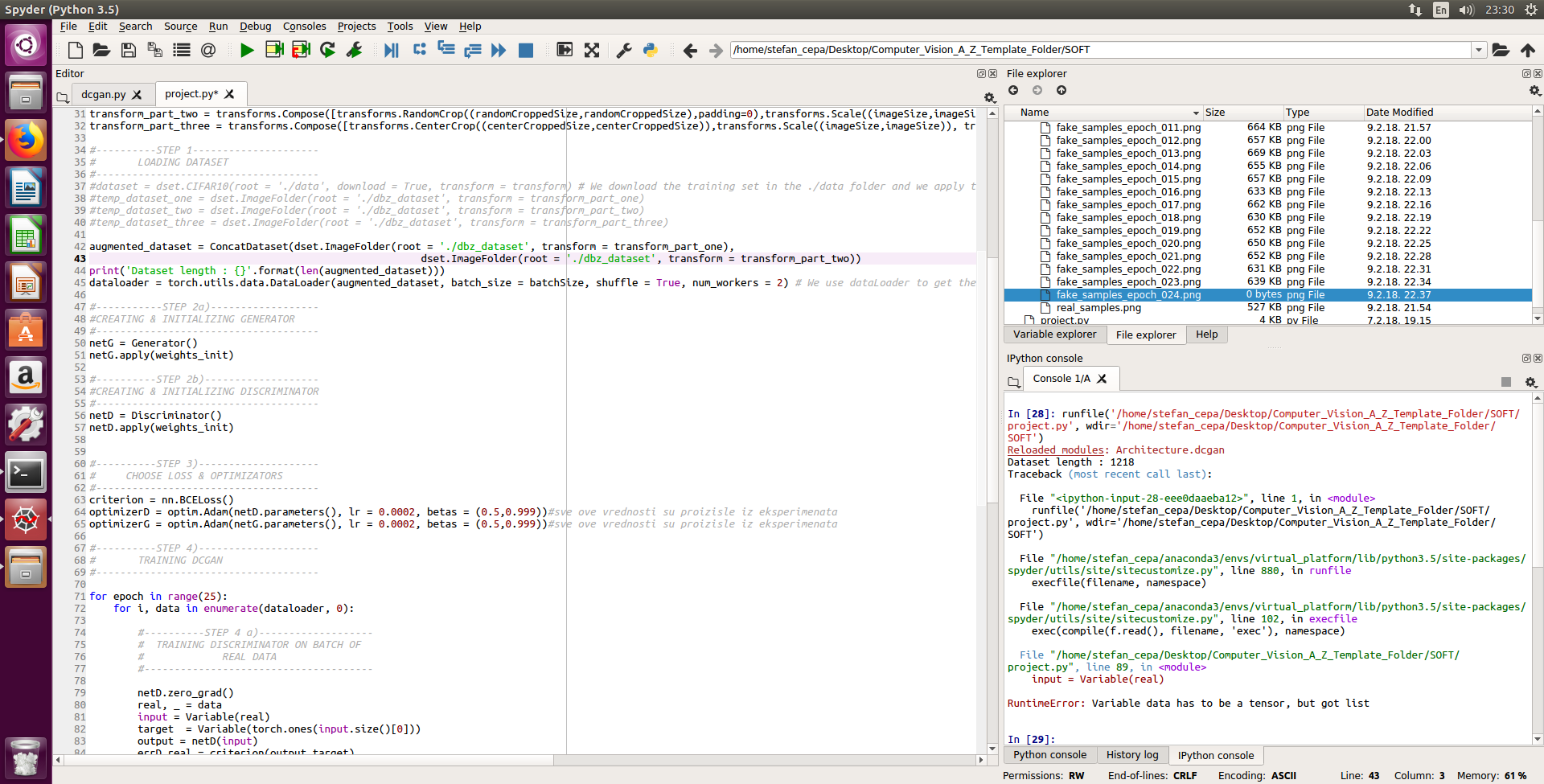
Line 42: im trying to merge two datasets which are loaded from the same path but performed different transformations on them - but when i print datasets len it saids 1218 (which is equal to a single dataset not two)
Line 89 (I think) - Error for some reason
I have a small dataset of only 1200 images. My idea was to to load dataset, perform lets say Random Crop on it, then load dataset again but this time perform ColorJitter and then merge those two datasets into one which will result in dataset of 2400 pictures. I wanted to create a dataset of atleast 7200 pictures ( which is 6 transformations each time i load dataset) . Do you by any chance have a better idea?
It’s strange that ConcatDataset does not throw an error, since its __init__ function only takes one argument and it looks like you’ve provided two (both datasets).
Try to create the ConcatDataset like this:
class MyData(Dataset):
def __init__(self):
self.data = torch.randn(100)
def __getitem__(self, index):
return self.data[index]
def __len__(self):
return len(self.data)
data1 = MyData()
data_loader1 = DataLoader(data1, batch_size=1)
for batch_idx, data in enumerate(data_loader1):
print(batch_idx) # prints to idx 99
data2 = MyData()
concat_data = ConcatDataset((data1, data2))
concat_loader = DataLoader(concat_data, batch_size=1)
for batch_idx, data in enumerate(concat_loader):
print(batch_idx) # prints to idx 199
print(len(data_loader1)) # 100
print(len(concat_loader)) # 200
I cannot see line 89. Would you please post the code snippet?
Generally, you could apply both transformations to your dataset.
Since transformations like RandomCrop are applied randomly, one cannot say it’s doubling your data size.
In each iteration your model will see a random transformation of your input.
I was able to concat the data sets but unable to separate the respective image tensors while enumerating. When I just print the data it shows both tensor values in concatenated way. If I try something like the following:
for batch_idx,(inp1,inp2) in enumerate(concat_loader):
it gives “ValueError: not enough values to unpack (expected 2, got 1)”
If i use zip the enumerator for loop goes into infinite loop.
How to solve this?
ConcatDateset will concatenate both datasets on top of each other, so that the number of samples will grow. It won’t return both samples for each index.
If you would like to do that, you could try to adapt this code:
class MyDataset(Dataset):
def __init__(self, dataset1, dataset2):
self.dataset1 = dataset1
self.dataset2 = dataset2
def __getitem__(self, index):
x1 = self.dataset1[index]
x2 = self.dataset2[index]
return x1, x2
def __len__(self):
return len(self.dataset1)
dataset1 = TensorDataset(torch.randn(100, 1))
dataset2 = TensorDataset(torch.randn(100, 1))
dataset = MyDataset(dataset1, dataset2)
Hi, Nick
Is there way I can edit the IMG_EXTENSIONS so that the ImageFolder would be able to read more image with .gif and .oct-stream extension?
Best
I just have a little question. Say the image folder is like this:
root/dog/xxx.png
root/dog/xxy.png
root/cat/123.png
root/cat/asd932_.png
Then I suppose it’s that the class dog is encoded into [1, 0] as for the first category, And the cat goes to [0, 1], Am I right?