Hi,
I am trying to understand how data parallel distributes loss and gradient back to each device for a backward pass after the forward pass.
I did a little experiment.
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
modules = [
torch.nn.Linear(10, 3),
torch.nn.Linear(3, 4),
torch.nn.Linear(4, 5),
]
self.net = torch.nn.ModuleList(modules)
def forward(self, inputs):
for i, n in enumerate(self.net):
inputs = n(inputs)
return inputs
def main():
X = np.random.uniform(-1, 1, (20, 10)).astype(np.float32)
y = np.random.randint(0, 5, (20,))
print(X.shape)
print(y.shape)
model = Net()
loss = torch.nn.CrossEntropyLoss()
#print('Model:', type(model))
#print('Loss:', type(loss))
X = torch.from_numpy(X)
y = torch.from_numpy(y)
print('X', X.size(), 'y', y.size())
if torch.cuda.is_available():
model = torch.nn.DataParallel(model)
print('Model:', type(model))
print('Devices:', model.device_ids)
model = model.cuda()
loss = loss.cuda()
X = X.cuda()
y = y.cuda()
else:
print('No devices available')
X = Variable(X)
y = Variable(y)
outputs = model(X)
l = loss(outputs, y)
print('Loss:', l)
if __name__ == '__main__':
main()
I got following results,

In my understanding, the loss should be in the format of [loss 1, loss 2, loss3, loss4] from the data parallel working diagram (first picture in the second row).
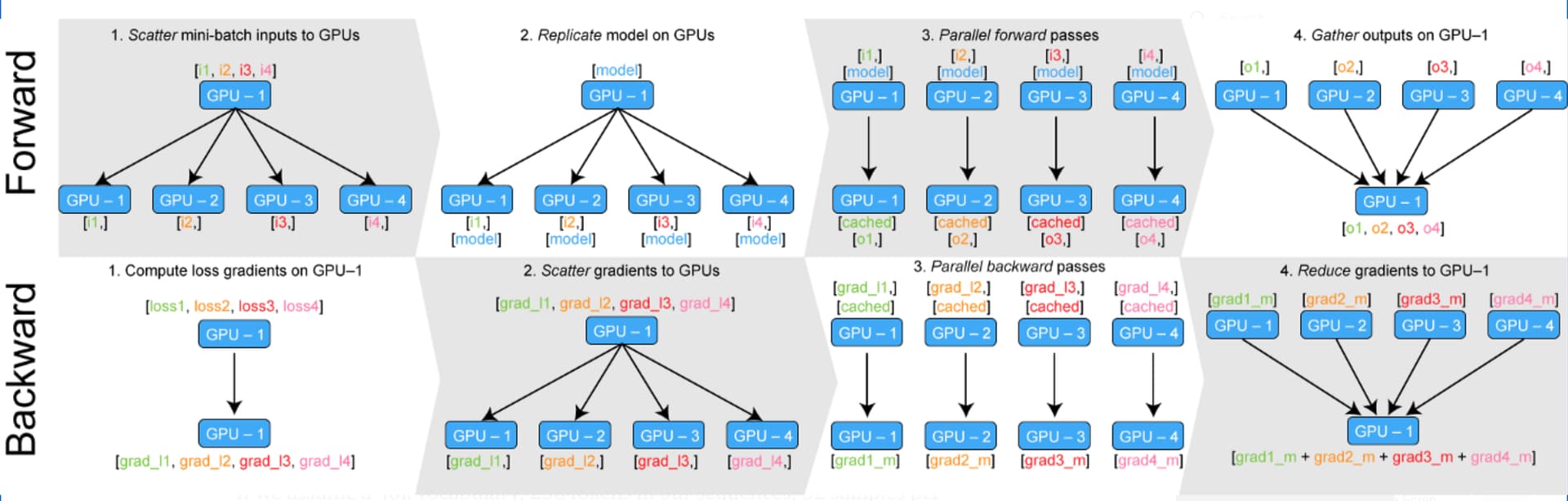
Why it is just a single number from the experiment code?