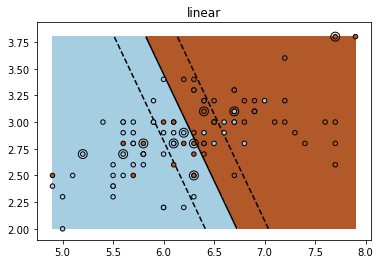
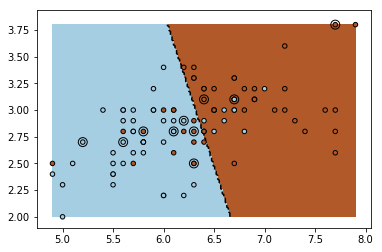
The paper Large Margin Deep Networks for Classification proposes to learn a large margin in neural networks. I tried to understant it via implement the most simplified case, the liner SVM as special case.
iris dataset is adopted
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets, svm
iris = datasets.load_iris()
X = iris.data
y = iris.target
X = X[y != 0, :2]
y = y[y != 0]
n_sample = len(X)
np.random.seed(0)
order = np.random.permutation(n_sample)
X = X[order]
y = y[order].astype(np.float)
X_train = X[:int(.9 * n_sample)]
y_train = y[:int(.9 * n_sample)]
X_test = X[int(.9 * n_sample):]
y_test = y[int(.9 * n_sample):]
The way SVM works:
# fit the model
for fig_num, kernel in enumerate(('linear', 'rbf', 'poly')):
clf = svm.SVC(kernel=kernel, gamma=10)
clf.fit(X_train, y_train)
plt.figure(fig_num)
plt.clf()
plt.scatter(X[:, 0], X[:, 1], c=y, zorder=10, cmap=plt.cm.Paired,
edgecolor='k', s=20)
# Circle out the test data
plt.scatter(X_test[:, 0], X_test[:, 1], s=80, facecolors='none',
zorder=10, edgecolor='k')
plt.axis('tight')
x_min = X[:, 0].min()
x_max = X[:, 0].max()
y_min = X[:, 1].min()
y_max = X[:, 1].max()
XX, YY = np.mgrid[x_min:x_max:200j, y_min:y_max:200j]
Z = clf.decision_function(np.c_[XX.ravel(), YY.ravel()])
# Put the result into a color plot
Z = Z.reshape(XX.shape)
plt.pcolormesh(XX, YY, Z > 0, cmap=plt.cm.Paired)
plt.contour(XX, YY, Z, colors=['k', 'k', 'k'],
linestyles=['--', '-', '--'], levels=[-.5, 0, .5])
plt.title(kernel)
plt.show()
The model defined
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.autograd import Variable
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.o_liner = nn.Linear(in_features=2, out_features=2)
parameters = [p for p in self.parameters() if p.requires_grad]
self.optimizer = optim.SGD(parameters, 0.01)
def forward(self, X):
probs = self.o_liner(X)
return probs
def update(self,X, y):
y_neg = 1 - y
X,y, y_neg = self.to_cuda([X,y, y_neg])
X.requires_grad=True
y = y.long()
y_neg = y_neg.long()
probs = self(X)
probs = F.sigmoid(probs)
fi_x = probs[range(y_neg.size(0)),y_neg]
fk_x = probs[range(y_neg.size(0)),y]
sum(fi_x-fk_x).backward()
ws = X.grad.data
ws_p = torch.sum(ws * ws, dim=1)
probs = self(X)
probs = F.sigmoid(probs)
fi_x = probs[range(y_neg.size(0)),y_neg]
fk_x = probs[range(y_neg.size(0)),y]
loss = 0.5-((fk_x-fi_x)/ (Variable(1e-6+ws_p)))
# loss = 0.5-((fk_x-fi_x)/ 1) # this loss function works fine
loss = loss[loss.data>0]
#if loss.size()
loss = sum(loss)
#loss = F.sigmoid(0.1 - (probs[y_neg]-probs[y]))
#loss = F.cross_entropy(probs, y)
#print(loss)
self.optimizer = self.optimizer
self.optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm(self.parameters(), 20.0)
self.optimizer.step()
return loss.data[0]
def to_cuda(self, np_array_list):
v_list = [Variable(torch.from_numpy(e).float()) for e in np_array_list]
return v_list
def predict(self,X):
X = self.to_cuda([X])[0]
probs = self(X)
psbs = F.sigmoid(probs) + 1
_, pred_y = torch.topk(psbs, k=1, dim=1)
return pred_y.data.cpu().numpy()
model = Model()
Model training
for i in range(15000):
loss = model.update(X_train, y_train-1)
if i%1000 == 0:
print(loss)
plt.figure(fig_num)
plt.clf()
plt.scatter(X[:, 0], X[:, 1], c=y, zorder=10, cmap=plt.cm.Paired,
edgecolor='k', s=20)
# Circle out the test data
plt.scatter(X_test[:, 0], X_test[:, 1], s=80, facecolors='none',
zorder=10, edgecolor='k')
plt.axis('tight')
x_min = X[:, 0].min()
x_max = X[:, 0].max()
y_min = X[:, 1].min()
y_max = X[:, 1].max()
XX, YY = np.mgrid[x_min:x_max:200j, y_min:y_max:200j]
Z = model.predict(np.c_[XX.ravel(), YY.ravel()])
Z = Z.reshape(XX.shape)
plt.pcolormesh(XX, YY, Z > 0, cmap=plt.cm.Paired)
plt.contour(XX, YY, Z, colors=['k', 'k', 'k'],
linestyles=['--', '-', '--'], levels=[-.5, 0, .5])
Questions:
- Whether the model is correctly implemented?
- Is there any way to forward only once? (two forward are used in update)
Other comments are appreciated, thanks!