Hi,
So I am running horovod distributed pytorch training on a machine with 16 GPUs. I see that the RAM constantly increases, and once it reaches 300GB horovod just errors out:
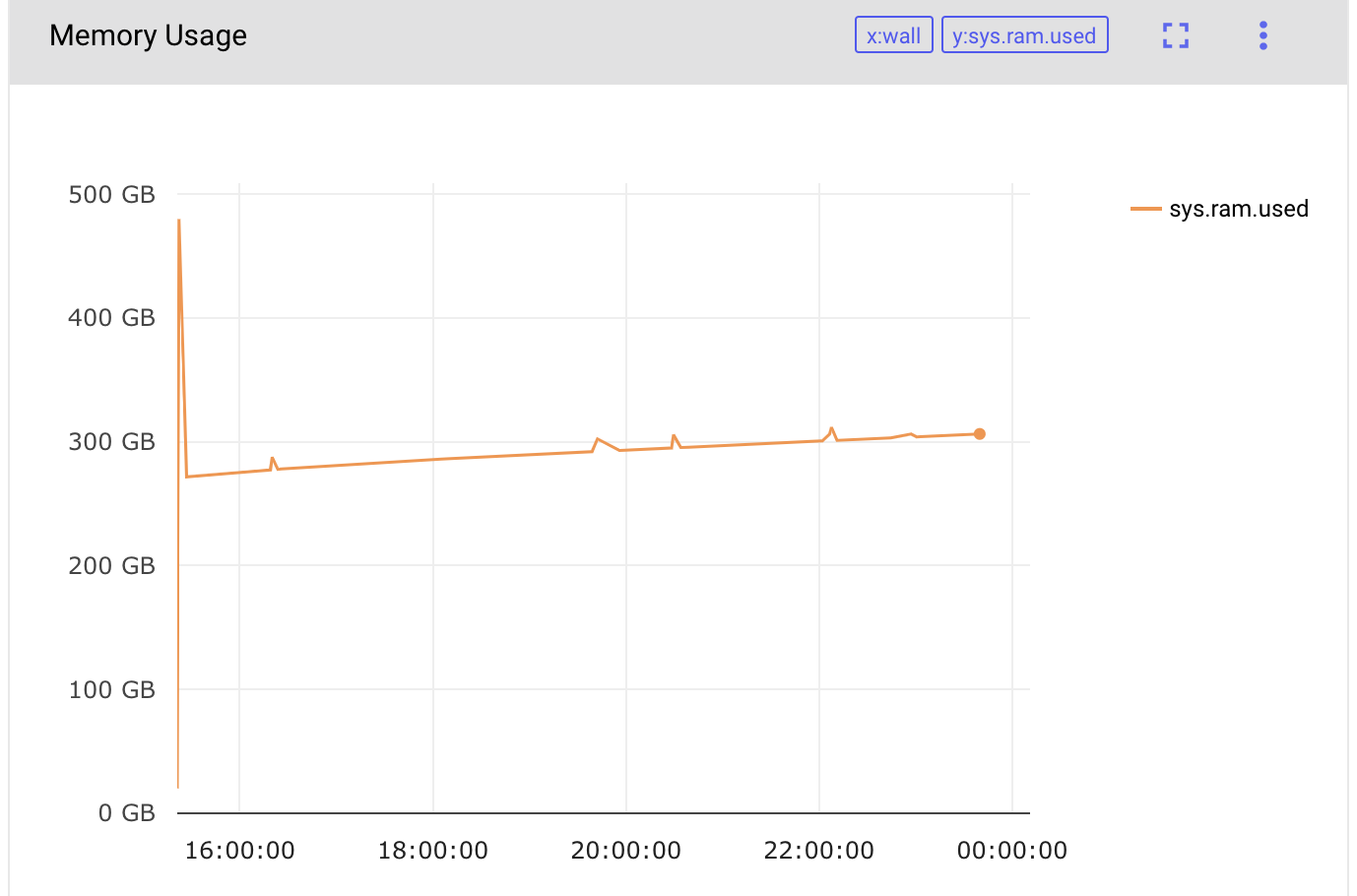
I tried to debug this issue with python memory profiler using only 1 GPU. I did a few training iterations, and here is the output from the profiler:

If I interpret this correctly, whenever I do loss = model(...), 63 MiB memory gets used and never gets returned (check increment column). So the problem seems to be this issue? Furthermore even after I included del loss on the bottom, the 63MiB is still not returned.
Can anyone share their insight on the root cause?
Thanks