When I use torch.nn.parallel.DistributedDataParllel for training , I found process launched for training on all other gpus would take up some memory at GPU 0 ,i.e worker 0. This take much more memory of GPU 0 that I can’t use bigger batch. How Can I solve this? Is it because other process send gradients to 0 by default to calculate the average???
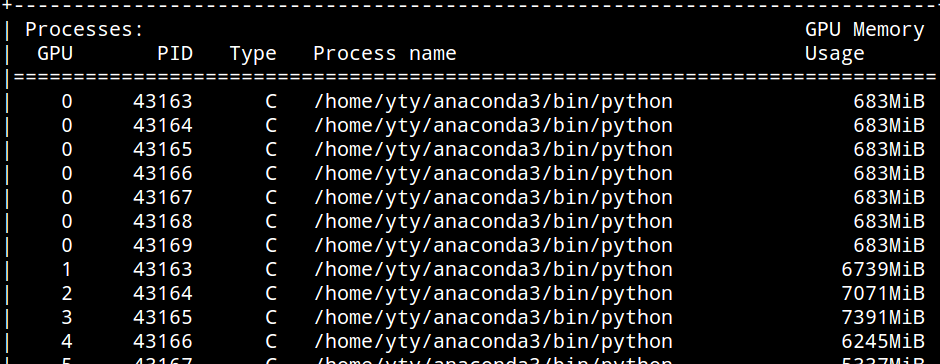
By the way in the screenshot, the process for training step on GPU0 was killed since it crashes due to outof memory error
hi, i meet same problem , have you solve it? thx