Thank you for all the amazing work on PyTorch and the dedication to open-source and community building.
As I’ve been diving in to understand better the many machine-learning frameworks that have arisen, I’ve been trying to see if consolidation is possible.
This post is to get discussion around the fork from Chainer that PyTorch started as and how to facilitate connecting back to the Chainer community (helping Chainer users migrate to PyTorch, and working with Chainer maintainers to determine if PyTorch can be their community) as well.
The Chainer devs are largely in Japan, but very accessible and talented. It is a shame that PyTorch and Chainer are not one effort.
Are there any thoughts on how to bridge these communities and help combine efforts again?
One challenge to collaboration is how fast the space is moving, and how many projects there are that are pursuing similar lines of work, but with slightly different constraints or goals.
Some diversification is valuable and very good, but it seems to me that we have more than needed.
I keep looking for common libraries that multiple projects can share.
One mantra I have come to understand is that: “Users want integrated solutions, but developers need separable libraries and common foundations”.
It can be tempting as a developer to just try and build everything rather than re-use foundations from other communities. In the long-run, however, factored solutions built on re-usable components are more easily maintained, adapted, and re-written.
Despite beginning my career in array-computing and applied math plus optimization (the foundations of what is now deemed machine learning), I’ve spent a decade on packaging precisely because good packaging enables the creation of useful, integrated solutions from more easily maintained components.
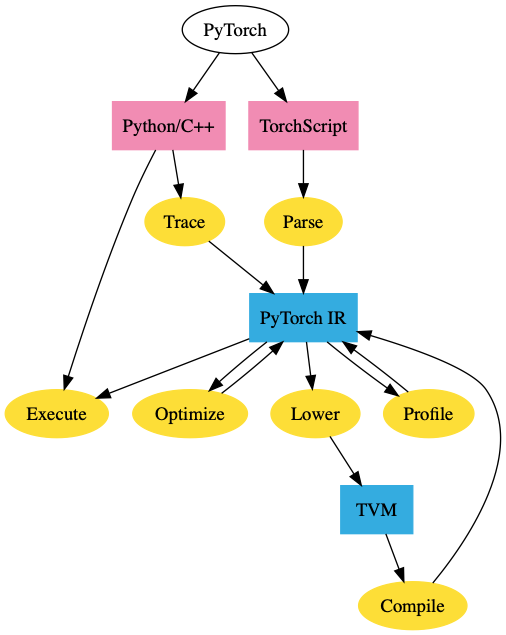
Does anyone know where to find PyTorch’s component diagram and how it sees its different parts and what libraries it depends on?
I do want to clarify that PyTorch was not a fork of Chainer in the literal sense. The frontend design was inspired by Chainer, but the devil is in the details – it was a full implementation of a frontend and engine with the backend connected to Torch-7’s C libraries.
Here’s more info: PyTorch Tutorial for Deep Learning Researchers - #3 by smth
As of today, the architecture diagram looks roughly like this:
We have had great meetings and chats with the Chainer team at various times, especially at conferences, but also in-person at their offices. Many positive things have come out, but not the ability to reconcile communities (unfortunately).