In such a situation would we need to explicitly list out each convolutional layer within the model definition? I understand each layer has an associated weight tensor and so I am not sure if we can simply re-use the layers.
Yes it is definitely possible! Whether or not you want to do it is a design decision. Broadly, it will lower memory cost while also reducing the degrees of freedom of the model.
One of the important contributions of DenseNet was the discovery that (for classification) you can pass the parameter tensors of early layers as inputs to deeper layers to reduce the memory cost of the model and encourage the model to learn features that are applicable at several scales.
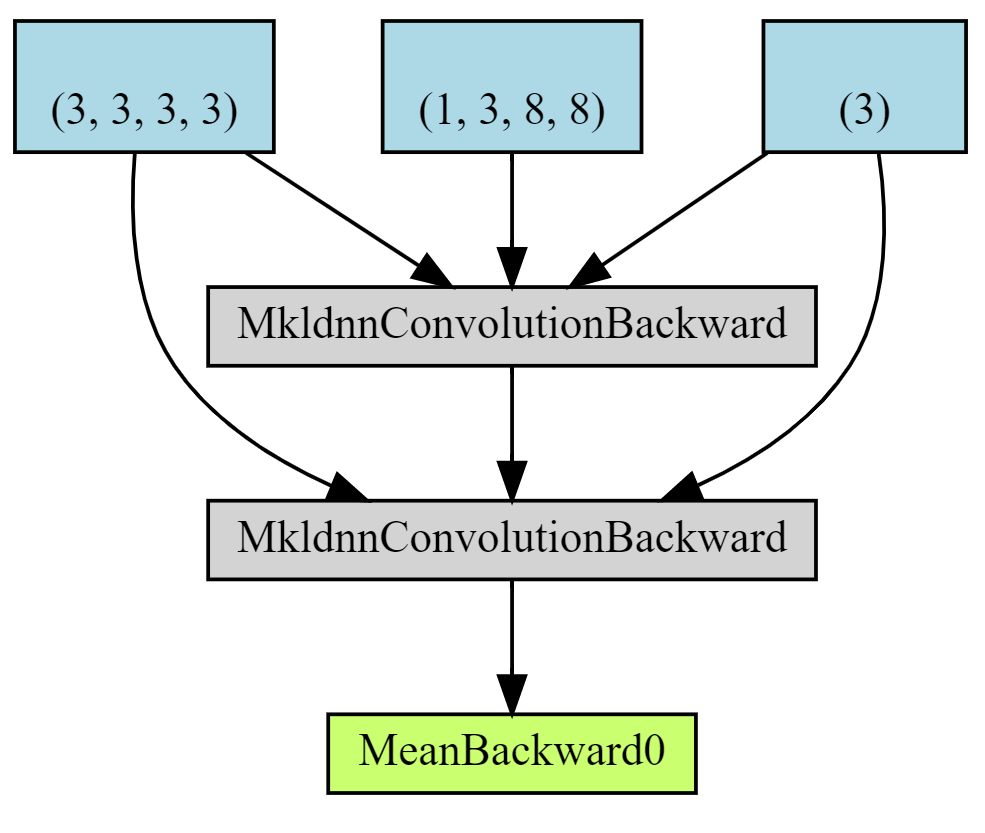
You could share the parameters themselves like:
c = nn.Conv2d(3, 3, (3, 3))
im = torch.randn(1, 3, 8, 8, requires_grad=True)
o = c(im)
o = c(o)
I am not sure if YOLO uses parameter sharing. I do seem to remember that YOLOv3 does use residual connections. But it would be an interesting experiment to see if the parameter sharing improves performance!
Thank you so much for the detailed explanation!
Just to confirm my understanding, reusing layers would effectively count as parameter sharing (using same weights)? And if so, is there a way to prevent such an occurrence without having to explicitly list out every layer?
Yes, reusing a layer would use the same parameters in its operation.
If you are dealing with a lot of (simple to initialize) layers, you could try to create them in a loop and append each one to a nn.ModuleList.
Later on you could pass the layers from this list to an nn.Sequential module or just call it again in a loop in your forward method.