I’m trying to recreate a semi-supervised GAN architecture for MNIST-data in Pytorch that was originally implemented in Keras in this blogpost.
In the blogpost, there are three possibilites outlined to implement the semi-supervised discriminator. I’m struggling with this one (“Stacked Discriminator Models With Shared Weights”):
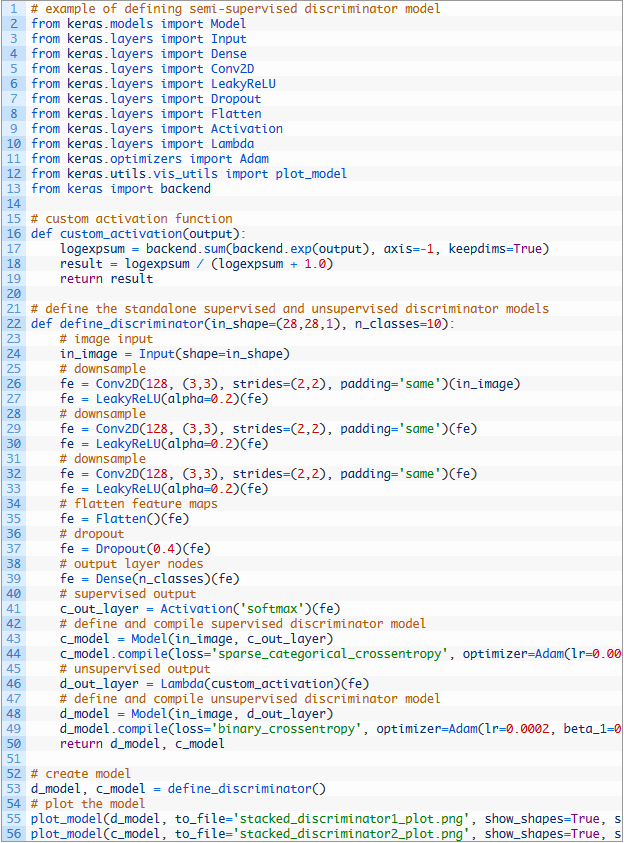
I’m redoing the model in Pytorch like this:
# Discriminator
class Discriminator(nn.Module):
def __init__(self, n_classes):
super(Discriminator, self).__init__()
# number of classes for the classifier
self.n_classes = n_classes
# layers the classifier model and discriminator model share
self.shared_layers = nn.Sequential(nn.Conv2d(in_channels=1, out_channels=128, kernel_size=3, stride=2, padding=15),
nn.LeakyReLU(negative_slope=0.2),
nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=2, padding=15),
nn.LeakyReLU(negative_slope=0.2),
)
self.dropout = nn.Sequential(nn.Dropout(p=0.4))
# output layer nodes
self.fc = nn.Sequential(nn.Linear(128*28*28, self.n_classes))
def forward(self, x):
x = self.shared_layers(x)
# flatten
x = x.view(-1, 128*28*28)
x = self.dropout(x)
x = self.fc(x)
# classifier output
c_out = F.softmax(x, dim=1)
# discriminator output
d_out = self.custom_activation(x)
return d_out, c_out
# to reuse the classifier output before softmax for the discriminator output
def custom_activation(self, x):
logexpsum = torch.sum(torch.exp(x), dim=1)
result = logexpsum / (logexpsum + 1.0)
return result
However, when training this model, the classifier part of the model is really bad, with a training accuracy below chance (below 10%). Can anyone give me hint about what I got wrong?