I’ve been profiling the inference stack that I’m using against vLLM and I found that in their case after calling graph replay, the first kernel gets executed almost instantly(left), whereas in my code(right) it is towards the end of graph.replay:
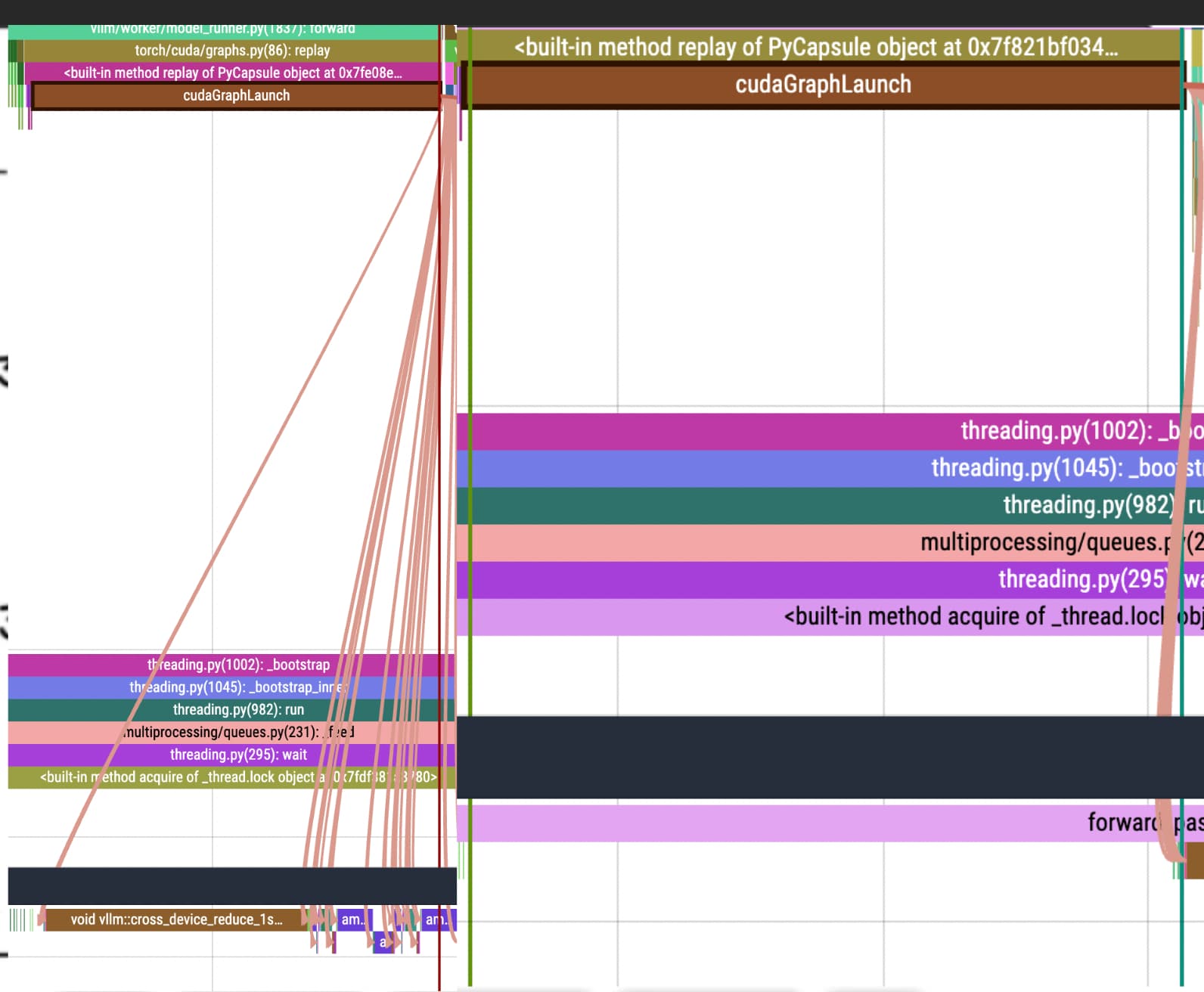
Does anyone have any insight on what might cause this big delay? Graph launch takes 1-2ms so it’s a big slowdown for me