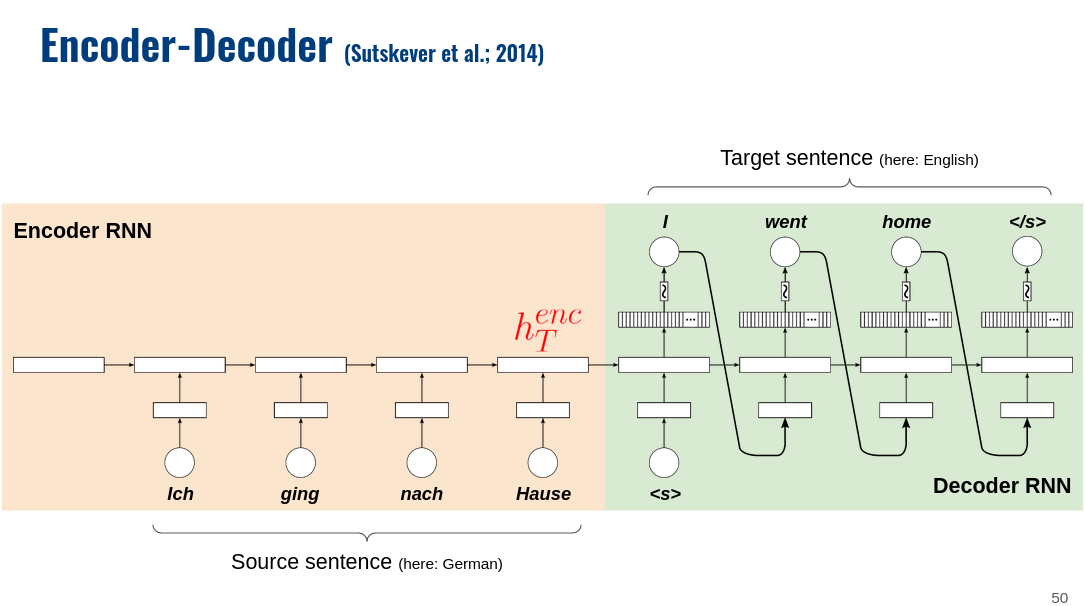
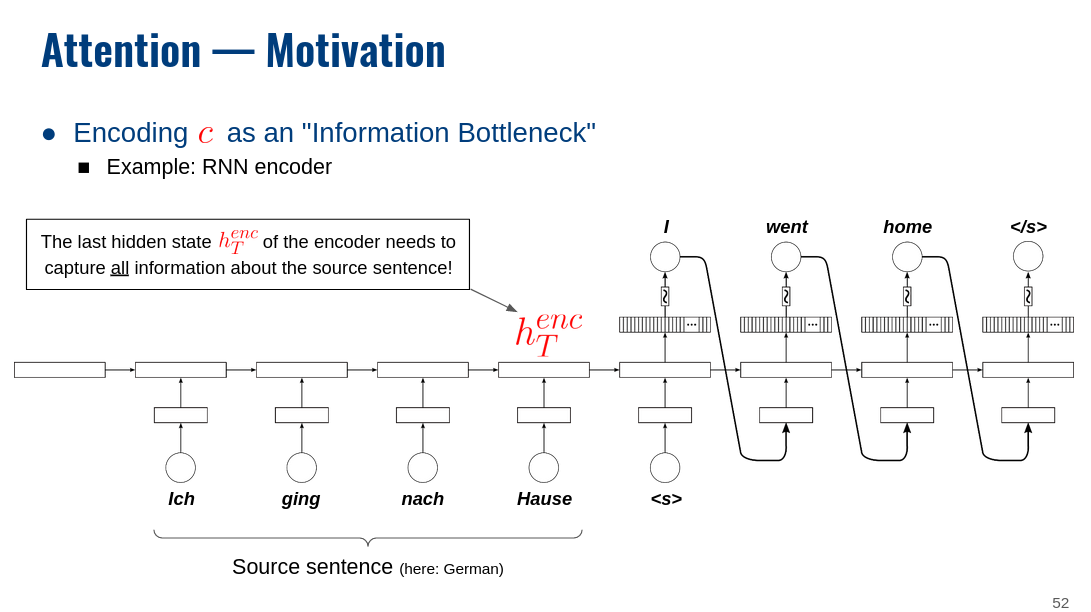
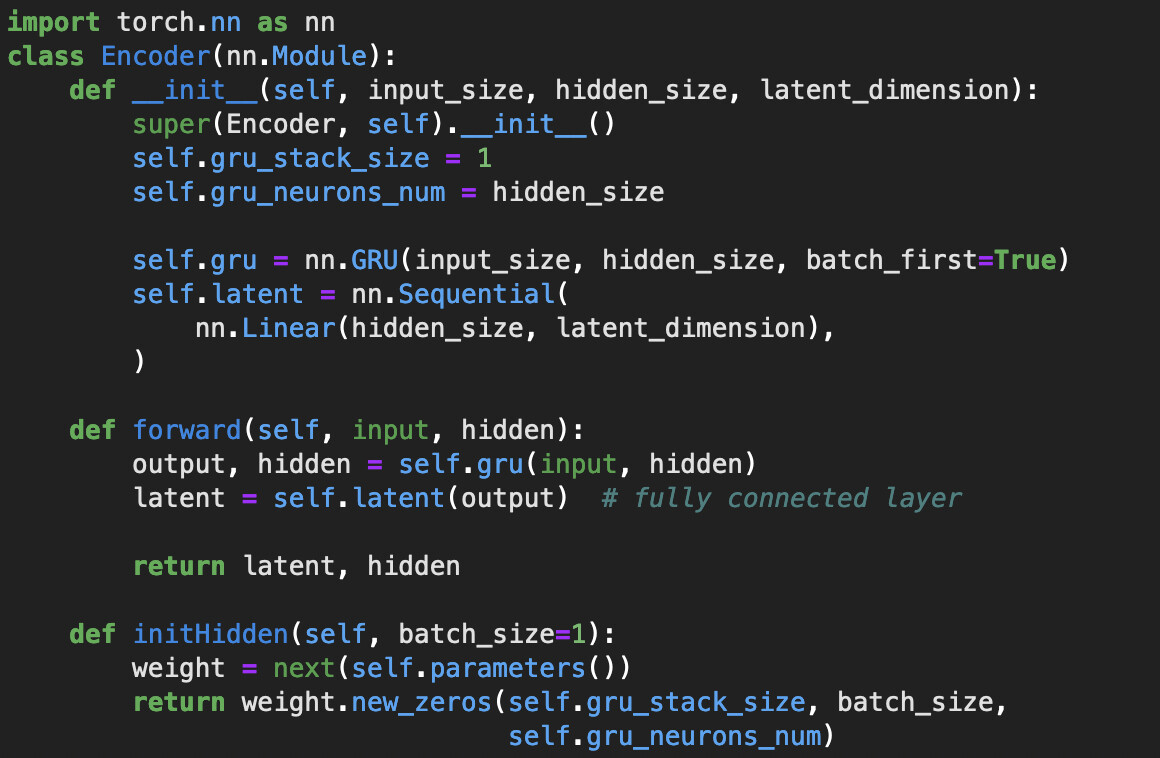
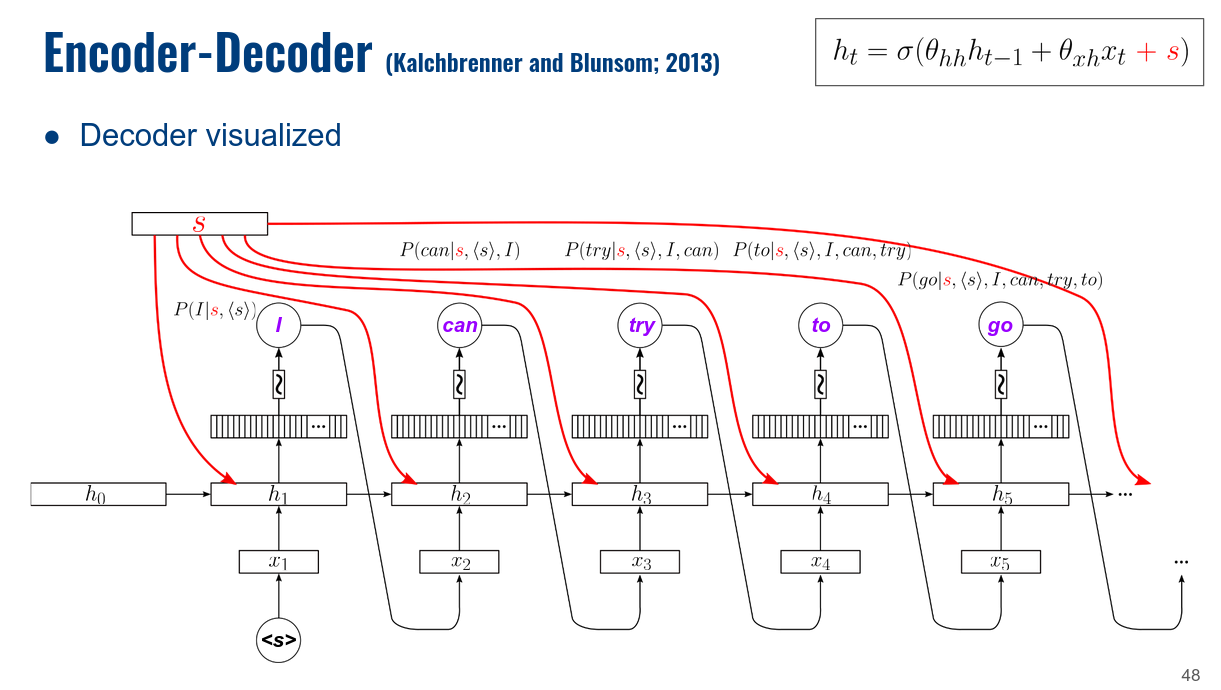
I am learning how to build a sequence-to-sequence model from a variety of sources and many of them show the input to a GRU unit to be an iteration over a sequence, for instance a series of one-hot encoded words in a sentence, alongside a hidden state that updates at each pass. Here is one of the tutorials I am referring to.
I am trying to replicate this in batch training but I am a bit confused by the documentation for GRUs. Given that we train RNNs by iterating through each token in a sequence, when would the sequence length ever be greater than one?
My data is fashioned such that batches are fed into the encoder in chunks [batch_size, maximum_token_length, num_features/one_hot_labels], and having batch_first = True on the GRUs.
Given this, what would be the difference between these two blocks of code?
for i in range(max_input_length):
latent, hidden = encoder(this_batch[:,i,:].reshape(batch_size,1, feature_size), hidden)
#vs
latent, hidden = encoder(this_batch, hidden)
Does the GRU just iterate through the sequence as I would with the for loop? Clearly this is the case when comparing output values from both methods. Why use one versus another?
Here is my yet-so-far unsuccessful training loop for an autoencoder with some notes to my thought process. The loss decreases incredibly slowly despite running on a GPU with a batch size of 32.

Am I fundamentally misunderstanding here or am I being impatient with training time? I’m getting meaningless reconstructions of sequences. I’m not sure if passing the latent representation from the encoder into the decoder at each time step is correct, and I am presuming the blank initialized hidden state would represent the token.
Any thoughts or help would be greatly appreciated! Thanks a lot.