Hi! I can offer at least some couple of thoughts:
-
I have a working implementation of RNN-based autoencoder you can have a look. It’s a bit verbose since I looked into support of a Variational Autoencoder which require to flatten the hidden state of the encoder. If you encoder and decoder have the same architecture (i.e., the hidden state have the same shape), then you can copy the last hidden state of the encoder over as the first hidden state of the decoder.
-
I’m a bit confused why you have a
decoder.initHidden()call in your code. In the bases Seq2Seq setup the hidden state of the decoder gets directly initialized with the last hidden state of the decoder. I’m also not really sure whatlatentas output of you encoder is, particularly compared tohidden(inlatent, hidden = encoder(...)) -
You have 2
reshape()calls. Make sure that these calls do exactly what you intend them to do. Sure, they fix your dimensions but they are likely to mess up your data. I’ve wrote a more detailed forum post on this since it’s such a common occurrence. Without really checking it, my money is that yourreshape()call are wrong :). -
From my experience, an Autoencoder for text can be difficult to train – an Variational Autoencoder even more so. I have so many epoch where the loss goes down slowly until at some point something “snaps in” in the loss goes down more significantly.
I hope that helps a bit.
EDIT: I was just seeing this sentence: “I’m not sure if passing the latent representation from the encoder into the decoder at each time step is correct, and I am presuming the blank initialized hidden state would represent the token.”
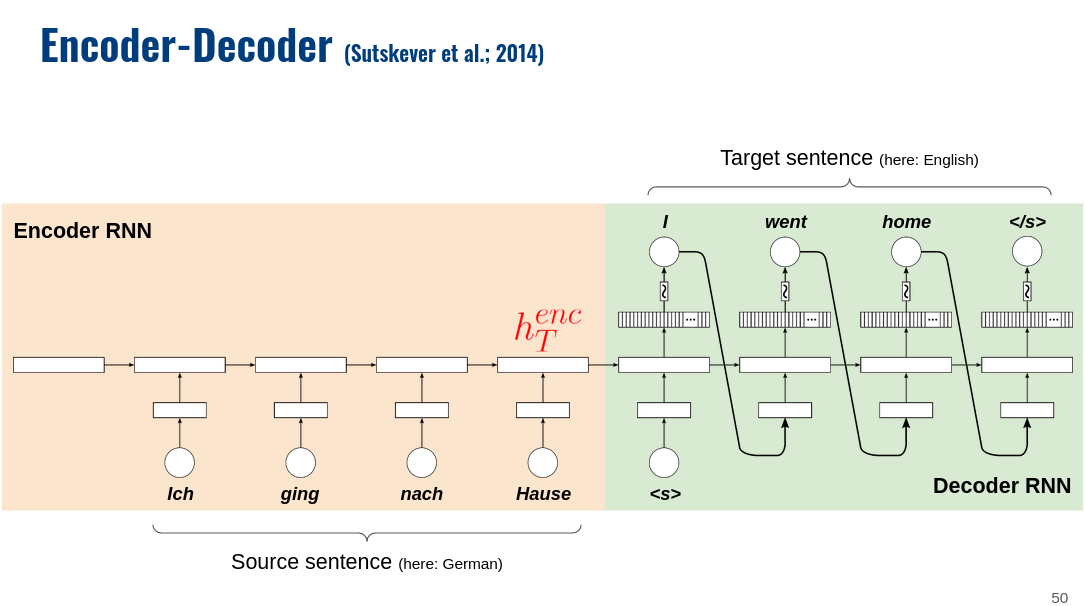
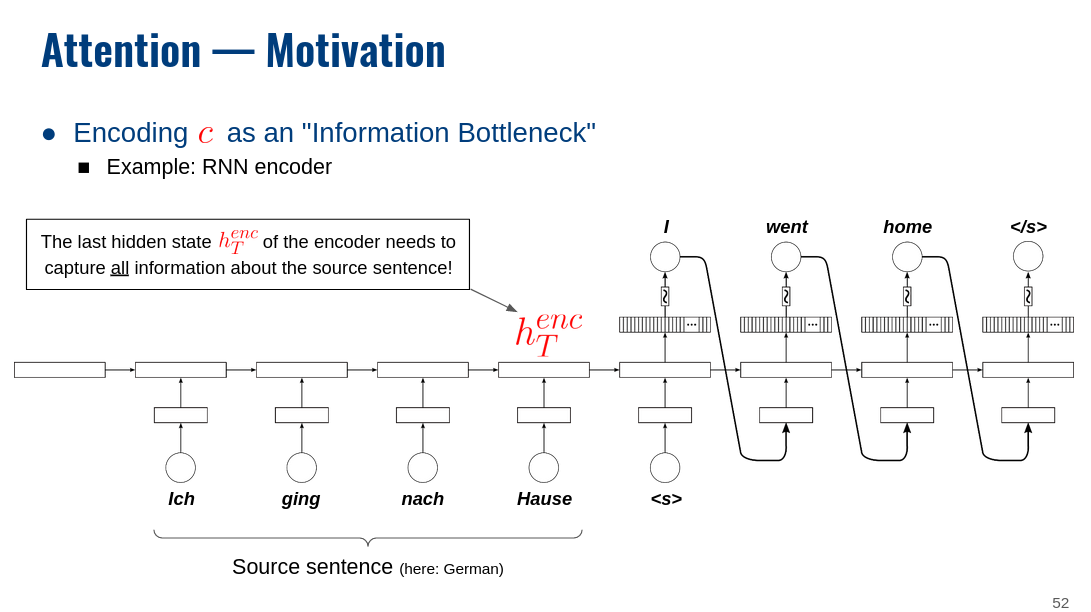
Again, the basic setup is that your input runs through the encoder. This gives you the last hidden state, which you then use as initial hidden state of the decoder. There is no passing of hidden states between the encoder and decoder at each time step. At least not in the basic encoder-decoder setup – I’m sure there are some more advanced techniques that do more fancy stuff. I’ve added below a couple of my lecture slides to visualize the idea.