Essentially I have two outputs from the encoder:
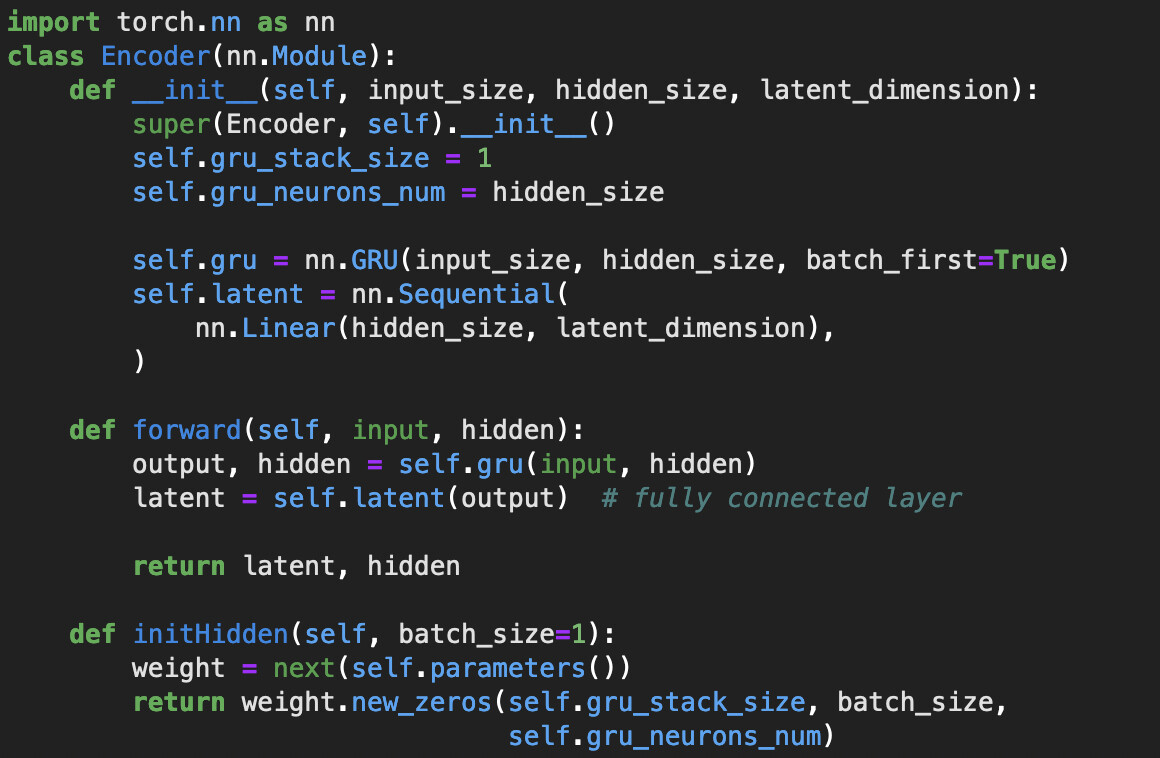
One being the GRU output and the other being the updated hidden vector that’s refed at each iteration. I guess at some point in my education I learned that the compressed bottleneck layer of an autoencoder is the latent space, and the hidden memory state of an RNN being its own separate concept.
That aside, my model is converging but still quite slow (loss from 110 to 80 over 10 hours on a tesla V100… only about 20 epochs though). You were totally right about my reshape calls being incorrect, and after checking all data flows everything is functioning as intended. At this point I feel that the training loop is correct and now I’m just trying to speed this up since my goal is to have a working autoencoder and eventually VAE in a tractable amount of time.
I noticed in your code you have options for bidirectionality and an embedding layer. I think I will next add an embedding layer since that seems to help a lot, then add an attention to create a Transformer model. Is there more I can do to keep improving the model? Can I train on multiple GPUs? It’s hard to get a sense as to whether I just have to truly train for days or if I’m just doing this inefficiently, but I can’t find good “time” benchmarks online anywhere. Should I make my batch size as large as my GPU can handle?
Sorry for the rapidfire questions, I feel that I’m real close now! Thanks again!!!