My task is to make multi labels classification which I choose CrossEntropyLoss to do so. However, I have to reimplement a CELoss function as the pytorch built-in CELoss only accept a single label tensor as target (shape [batch, ]). Here is the loss part of my code:
# using built-in loss function
'''
labels[:, 1:] = 0 # to debug, I simplify the task to single label classification.
labels = labels.sum(-1)
logits = logits.view(-1, class_num)
labels = labels.view(-1)
loss_fct = CrossEntropyLoss()
loss = loss_fct(logits, labels)
'''
# my implementation
bs, label_num = labels.size()
labels[:, 1:] = 0
log_softmax_output = torch.log(F.softmax(logits, dim=-1))
log_softmax_output = log_softmax_output.view(-1, class_num)
w = torch.arange(label_num, dtype=logits.dtype, device=logits.device).view(1, label_num).tile([bs, 1])
nonzero_label_num = (labels > 0).to(logits.dtype).sum(dim=-1, keepdim=True)
w = ((nonzero_label_num - w) / nonzero_label_num) * (labels > 0).to(logits.dtype)
labels = labels.view(-1, label_num)
w = w.view(-1, label_num)
w = w[labels > 0] #[batchsize * nonzero_label_num]
relevant_logits = torch.gather(log_softmax_output, dim=-1, index=labels)
relevant_logits = relevant_logits[labels > 0] * w
loss2 = -relevant_logits.mean()
#print(loss, loss2)
The labels is a list zero-padding to a fixed label_num and the nonzero_label_num denotes actual class num of this sample. The label importance decrease from index 0 to nonzero_label_num which I use w to represent the multi labels importance. The problem becomes a common single label classification when I set label[:, 1:] = 0.
Under the single label prediction condition (to debug the code), I ran the code and the output shows that loss and loss2 are equal.
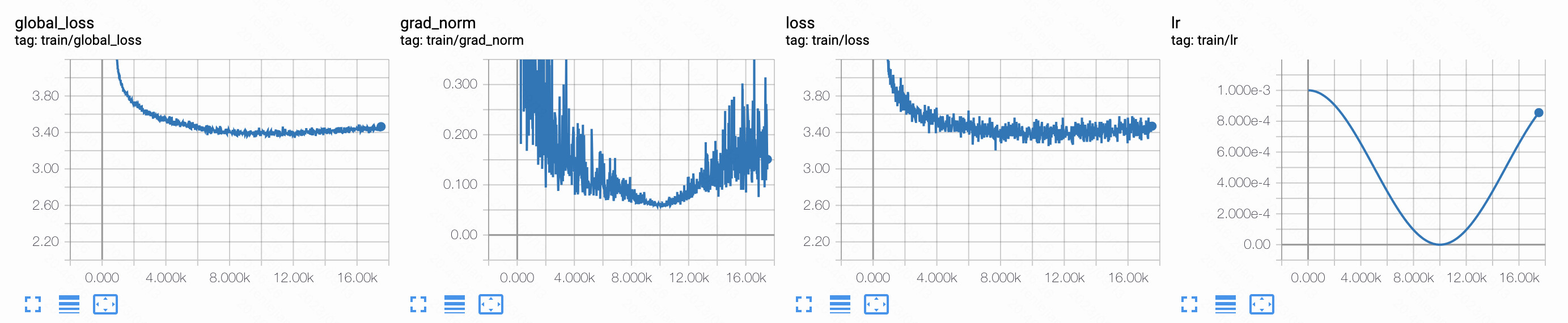
But the strange thing appears when the training procedure comes to a specific step. The gradients stop changing in the second implementation as well as the cosine LR_scheduler,
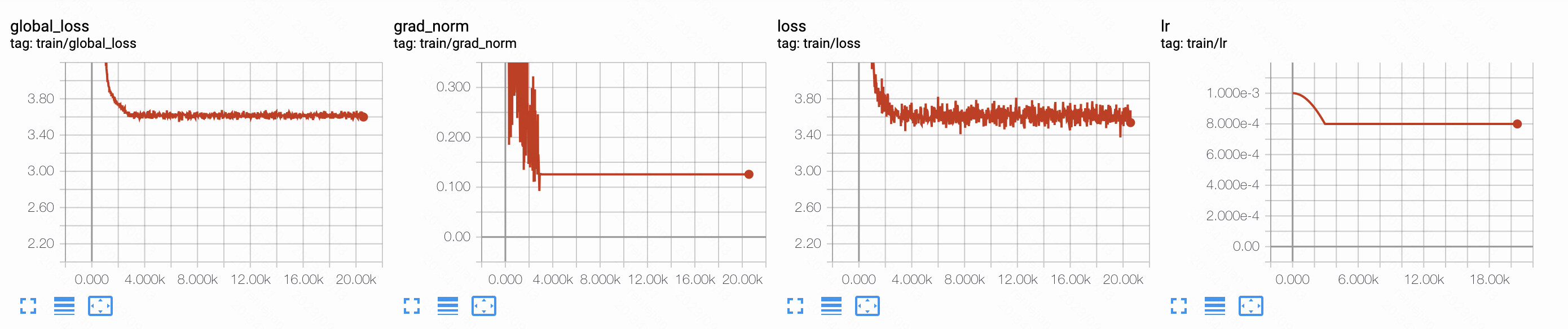
while the built-in implementation works fine.
So what’s the problem? Can any one help? Thanks so much.