Hi everyone,
I´m trying to implement REINFORCE as described in Sutton

However it doesn´t seem to be learning. Bellow is the code for the train function (using Gymnasium CartPole-v1)
´´´
def train(ep, policy, optimizer, gamma=1):
G = 0
for t in range(len(ep)-1):
st, at, rt = ep[t]
G = rt + gamma * G
pi = torch.log(policy(st)[at]) # My NN last layer is a softmax
loss = -G*pi
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(policy.parameters(), 1.)
optimizer.step()
´´´
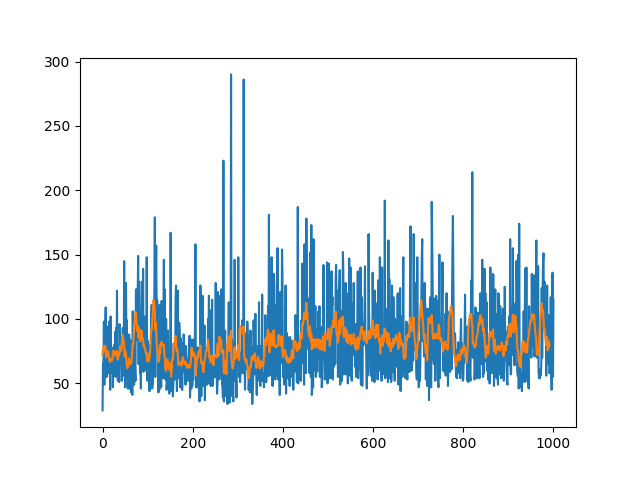
What it does is basicaly choose to ways, go for a real bad policy, averaging 10 for the rewards (while a random agente usually scores in the ~20s) or learn a little bit and stay arround 80 avg reward.
First I thought that the policy was changing to abruptly so I inserted the clip_grad_norm_, which increased the amount of time the agent got stucked at the 80ish but didn´t did much else (maybe got stucked in some local minima?)
I tried to play with weight initialization, net archetecture but to no avail. I would appreciate if someone could shed light in what maybe the issue.