Hi guys,
Is there any overfitting related with t-SNE visualization?
For example, If I get more divided and separate map from t-SNE than the previous,
can I say that it’s more overfitted than the previous?
I hope you answer any thoughts about it!
Thanks.
I think while a t-SNE plot might give you some information about the class separation, I think the training vs. validation losses should be better used to claim less overfitting.
t-SNE might output a lot of “good” and “bad” visualizations in my experience depending on the arguments you are passing to it, so I wouldn’t rely on its outcome regarding overfitting.
Hi ptrblck,
Thank you for your reply. I’ve been always motivated from your answers.
To make it clear, I have one more question.
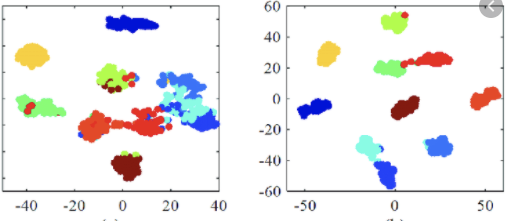
If there are two t-sne plots from two different models trained individually,
and I cannot say that which one is more generalizable?
I know the right one is more trained and yields better accuracy but,
if the features are more entangled, is there any chance to be more overfitted?
I think your general statement is true.
If the features (in the high dimensional feature space) are more entangled, then the model would have a harder time to separate the classes.
My only concern is how to capture this “entanglement”.
While t-SNE can certainly create your nice plots, I’m always skeptical about the chosen parameters for the t-SNE call.
If you are using sklearn.manifold.TSNE, are you using the default arguments and are other arguments always yielding a comparable output for both models?
That being said, I don’t want to discourage you using t-SNE, as it’s a great technique, and would recommend to also use the losses to describe the overfitting of a model.
I totally agree with you.
It yields sometimes good and sometimes bad plots, while changing the arguments.
I think I just refer to the distribution approximation, but not the exact criteria about like generalization or something.
Thank you for your time 