I am trying to replicate CNN model based on paper that I found.
But during training, I didn’t get the same result as the author said.
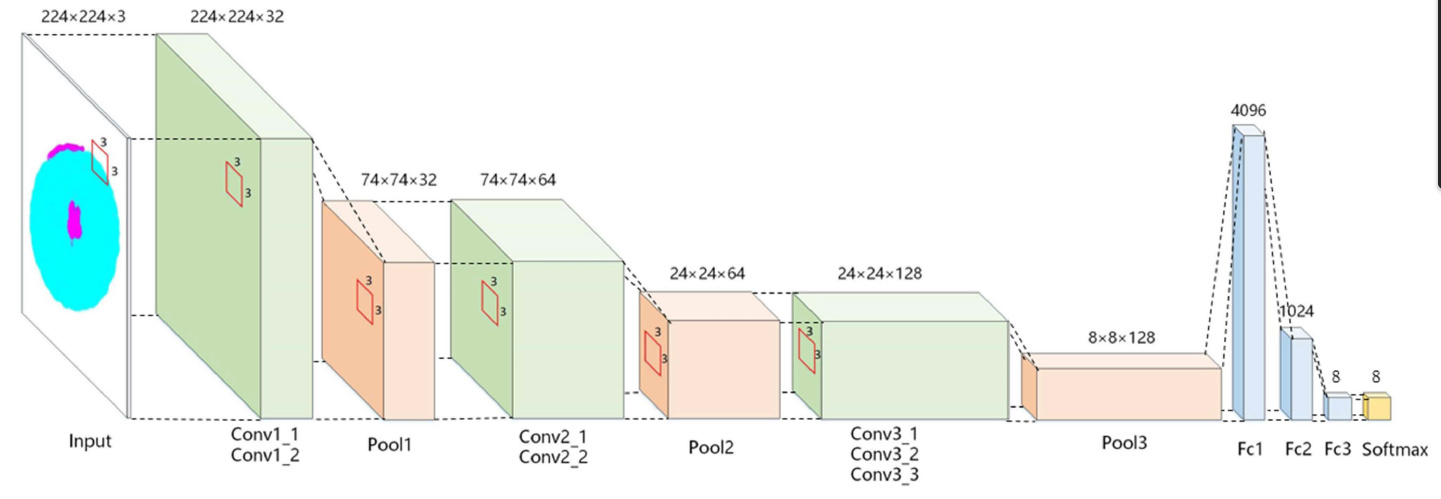
This is the paper model.
Blockquote
The input of the model is 224x224, the Convl to Conv3 are
the convolution layers, convolution kernel size is 3x3, the
stride value is 1 and use Rectified Linear Unit to activate.
After each convolutional layer, a 3 x 3 maximum pooling layer
is used for down-sampling. To avoid overfitting, the Dropout
method was introduced to the Fcl layer during training to
randomly inactivate many neurons. The Dropout probability
value was set to 0.5 in this method. The activation function
of Fcl layer is Sigmoid, and a Softmax layer is used for
calculating class probability.
import torch.nn as nn
import torch.nn.functional as F
train_on_gpu = torch.cuda.is_available()
# define the CNN architecture
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# convolutional layer
self.conv1_1 = nn.Conv2d(3, 32, 3)
self.conv1_2 = nn.Conv2d(32, 64, 3)
# max pooling layer
self.pool = nn.MaxPool2d(3, 3)
self.conv2_1 = nn.Conv2d(64, 64, 3)
self.conv2_2 = nn.Conv2d(64, 64, 3)
self.conv3_1 = nn.Conv2d(64, 128, 3)
self.conv3_2 = nn.Conv2d(128, 128, 3)
self.conv3_3 = nn.Conv2d(128, 128, 3)
self.dropout = nn.Dropout(0.5)
self.fc1 = nn.Linear(128*5*5, 1024)
self.fc2 = nn.Linear(1024, 8)
self.fc3 = nn.Linear(8, 8)
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
# add sequence of convolutional and max pooling layers
x = F.relu(self.conv1_1(x))
#print('conv1_1:',x.shape)
x = self.conv1_2(x)
x = self.pool(x)
#print('conv1_2:',x.shape)
x = F.relu(self.conv2_1(x))
#print('conv2_1:',x.shape)
x = self.conv2_2(x)
#print('conv2_2:',x.shape)
x = self.pool(x)
x = F.relu(self.conv3_1(x))
#print('conv3_1:',x.shape)
x = self.conv3_2(x)
#print('conv3_2:',x.shape)
x = F.relu(self.conv3_3(x))
#print('conv3_3:',x.shape)
x = self.pool(x)
#print('lastpool:',x.shape)
#x = self.dropout(x)
#print(x.shape)
x = x.view(-1,128*5*5)
#print('reshape:',x.shape)
x = self.dropout(torch.sigmoid(self.fc1(x)))
#print('fc1:',x.shape)
x = self.dropout(torch.sigmoid(self.fc2(x)))
#print('fc2:',x.shape)
x = self.softmax(self.fc3(x))
#print('fc3:',x.shape)
return x
# create a complete CNN
model = Net()
print(model)
# move tensors to GPU if CUDA is available
if train_on_gpu:
model.cuda()
#model=nn.DataParallel(model,device_ids=[0,1])#train on 2 GPU
Is my code wrong? I try to print each layer output but the size is not the same.
Maybe that is why I didn’t get the same result.
I am beginner at pytorch and python. I study electronics before.