Dear Community,
I’m trying to reproduce a simple over-fitting experiment on autoencoders, I got matching initialization under control but the loss and results would diverge over time.
Focus on the first 10 steps, we could see they are initualizaed the same.
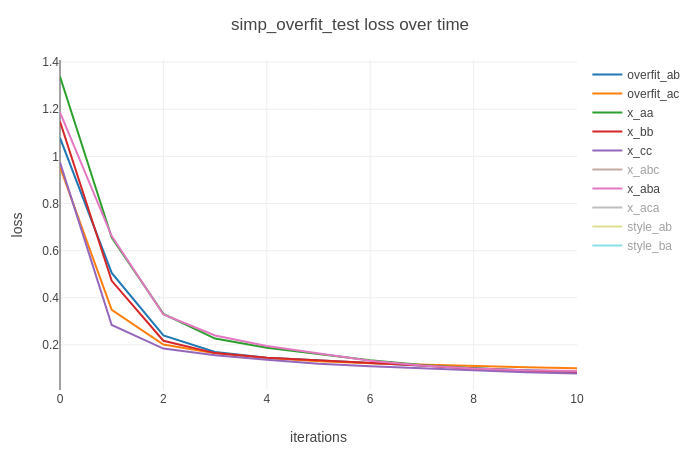
Then as training goes further, the curves will diverge a lot more
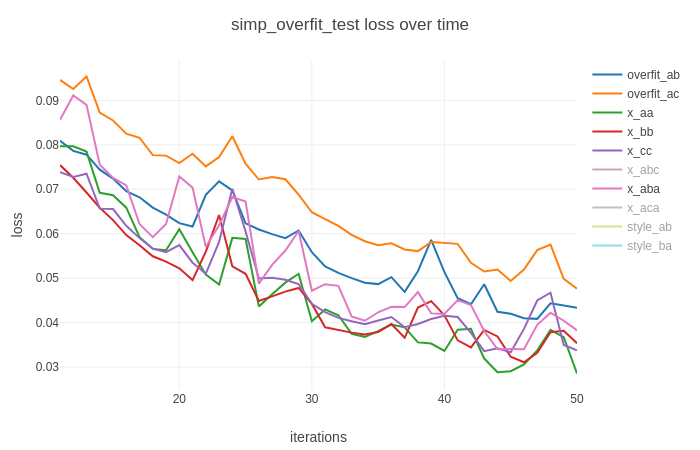
I found multiple discussions on reproducing and deterministic here already. For example [1], [2], [3], [4]
From the document we have REPRODUCIBILITY [4], MULTIPROCESSING BEST PRACTICES [5], Asynchronous execution [6].
I have followed all the suggestions and confirmed that I got matching random number and matching initialized weights (diff all the weights and 100% match) in my modules between tests. But my results always end up different.
Combining all previous discussion, here is what I did, at the beginning of my main.py
import numpy
numpy.random.seed(123)
import random
random.seed(123)
import torch
import torch.nn as nn
import torch.optim as optim
import torch.backends.cudnn as cudnn
from torch.autograd import Variable
torch.backends.cudnn.enabled = False
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
torch.manual_seed(123)
torch.cuda.manual_seed(123)
In data loader, num_workers=0. There are only two training samples so no shuffle there, flipping turned off.
In the terminal, I set CUDA_LAUNCH_BLOCKING=1 python ./main.py
Any other non-deterministic behavior during convolution or back propagation that we need to consider?
Thank you!
Just tried replacing Adam with SGD and the problem remains.