I am trying to reproduce ResNet 32 (34) on CIFAR 10. Instead of coding all of the layers by myself I decided to start with PyTorch ResNet34 implementation.
From the paper we can read (section 4.2) that:
- used TEST set for evaluation
- augmentation: 4x4 padding and than crop back to 32x32 fro training images, horizontal flip, mean channels
- mini batch 128
- lr=0.1 and after 32k iterations lowered it to 0.01, after 48k to 0.001 and terminated at 64k
- weight decay= 0.0001 and momentum 0.9
However, later on they write:
We start with a learning rate of 0.1, divide it by 10 at 32k and 48k iterations, and terminate training at 64k iterations, which is determined on a 45k/5k train/val split.
Anyway, I do not use VALidation in this example.
Accuracy that they achieved is around 93%, however my best is about 85.
My transformation:
train_transform = transforms.Compose(
[transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.49139968, 0.48215841, 0.44653091), (0.24703223, 0.24348513, 0.26158784))])
Hyper-parameters:
model = models.resnet34(pretrained=False)
model.fc.out_features = 10
criterion = nn.CrossEntropyLoss()
exp_lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=90, gamma=0.1)
optimizer = optim.SGD(model.parameters(), lr=1e-1, momentum=0.9, weight_decay=1e-4)
Results:
Epoch 0/135 Loss: 1038.4823 Train Acc: 0.1741 Test Acc: 0.2400 Time: 28.56s
Epoch 1/135 Loss: 759.1835 Train Acc: 0.2692 Test Acc: 0.3251 Time: 14.81s
Epoch 2/135 Loss: 710.6933 Train Acc: 0.3076 Test Acc: 0.3539 Time: 15.13s
Epoch 3/135 Loss: 664.5496 Train Acc: 0.3561 Test Acc: 0.4033 Time: 15.31s
Epoch 4/135 Loss: 620.5696 Train Acc: 0.4105 Test Acc: 0.4568 Time: 15.49s
...
Epoch 11/135 Loss: 441.2646 Train Acc: 0.5948 Test Acc: 0.6277 Time: 14.91s
Epoch 12/135 Loss: 419.9310 Train Acc: 0.6179 Test Acc: 0.6228 Time: 15.77s
Epoch 13/135 Loss: 399.2816 Train Acc: 0.6366 Test Acc: 0.6565 Time: 15.59s
...
Epoch 20/135 Loss: 318.1587 Train Acc: 0.7158 Test Acc: 0.7324 Time: 15.39s
Epoch 21/135 Loss: 307.4588 Train Acc: 0.7257 Test Acc: 0.7226 Time: 15.50s
Epoch 22/135 Loss: 301.9478 Train Acc: 0.7312 Test Acc: 0.7219 Time: 14.99s
Epoch 23/135 Loss: 292.6665 Train Acc: 0.7387 Test Acc: 0.7279 Time: 15.03s
Epoch 24/135 Loss: 286.7134 Train Acc: 0.7455 Test Acc: 0.7282 Time: 15.61s
Epoch 25/135 Loss: 283.8343 Train Acc: 0.7479 Test Acc: 0.7430 Time: 14.74s
Epoch 26/135 Loss: 278.9446 Train Acc: 0.7510 Test Acc: 0.7202 Time: 15.03s
Epoch 27/135 Loss: 272.9502 Train Acc: 0.7574 Test Acc: 0.7619 Time: 15.16s
Epoch 28/135 Loss: 268.5519 Train Acc: 0.7609 Test Acc: 0.7401 Time: 14.79s
Epoch 29/135 Loss: 263.5728 Train Acc: 0.7659 Test Acc: 0.7733 Time: 15.56s
Epoch 30/135 Loss: 256.0966 Train Acc: 0.7729 Test Acc: 0.7597 Time: 15.08s
Epoch 31/135 Loss: 254.0941 Train Acc: 0.7752 Test Acc: 0.7685 Time: 14.98s
Epoch 32/135 Loss: 249.6497 Train Acc: 0.7772 Test Acc: 0.7696 Time: 15.29s
Epoch 33/135 Loss: 246.0313 Train Acc: 0.7802 Test Acc: 0.7848 Time: 15.22s
Epoch 34/135 Loss: 241.2385 Train Acc: 0.7873 Test Acc: 0.7501 Time: 15.54s
Epoch 35/135 Loss: 239.4684 Train Acc: 0.7886 Test Acc: 0.7596 Time: 14.96s
Epoch 36/135 Loss: 236.9835 Train Acc: 0.7898 Test Acc: 0.7543 Time: 15.34s
...
Epoch 85/135 Loss: 160.1628 Train Acc: 0.8583 Test Acc: 0.8082 Time: 15.07s
Epoch 86/135 Loss: 159.6879 Train Acc: 0.8581 Test Acc: 0.8171 Time: 14.77s
Epoch 87/135 Loss: 156.7326 Train Acc: 0.8605 Test Acc: 0.7995 Time: 14.76s
Epoch 88/135 Loss: 153.8567 Train Acc: 0.8638 Test Acc: 0.8191 Time: 15.01s
Epoch 89/135 Loss: 107.1789 Train Acc: 0.9036 Test Acc: 0.8503 Time: 14.77s
Epoch 90/135 Loss: 90.4571 Train Acc: 0.9185 Test Acc: 0.8532 Time: 14.74s
Epoch 91/135 Loss: 85.0465 Train Acc: 0.9241 Test Acc: 0.8526 Time: 14.75s
...
Epoch 133/135 Loss: 30.1169 Train Acc: 0.9729 Test Acc: 0.8526 Time: 14.80s
Epoch 134/135 Loss: 32.1346 Train Acc: 0.9711 Test Acc: 0.8469 Time: 14.83s
Epoch 135/135 Loss: 29.4413 Train Acc: 0.9727 Test Acc: 0.8491 Time: 14.76s
There are a few problems with this network.
- in first ~20 epochs TEST error is lower than TRAINING error
- after ~13 epochs (5K iterations) Log loss starts flickering (can be seen on the image below)
- after ~36/40 epochs starts showing signs of overfitting
- after epoch 89 LR has been decreased to 0.01
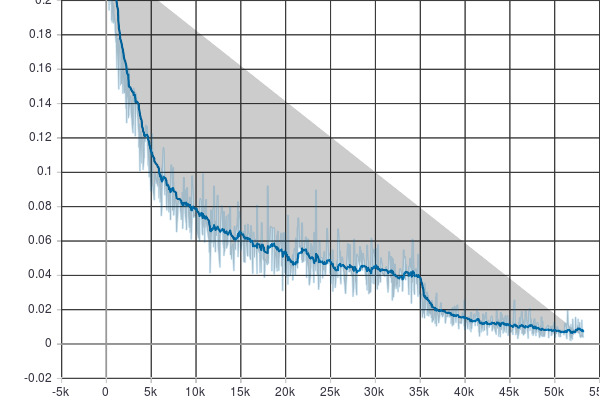
I believe that is not really correct that TEST error for first epochs in higher than for TRAIN data, filtering of LOSS function Is pretty strong after 13 epochs, maybe I should decrease learning rate easier? But that would probably overfit even quicker!
But THE MOST important question is how to reproduce similar results to those in the paper? I am overfitting very badly! To fix that I could use heavy augmentation and use additional regularisation, but I am trying to reproduce model from the paper thus I am following their instructions. Do you have any tips?