I’m running into a knowledge block.
I want to make a simple binary classifiyer. I took a deep dive into padded/packed sequences and think I understand them pretty well. After perusing around and thinking about it, I came to the conclusion that I should be grabbing the final non-padded hidden state of each sequence, so that’s what I tried below:
Classifier
class TextClassificationModel(nn.Module):
def __init__(self, vocab_size, embed_dim, hidden_size, num_class):
super(TextClassificationModel, self).__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim, padding_idx=0)
self.lstm = nn.LSTM(embed_dim, hidden_size, batch_first=True)
self.fc1 = nn.Linear(hidden_size, num_class)
def forward(self, padded_seq, lengths):
# embedding layer
embedded_padded = self.embedding(padded_seq)
packed_output = pack_padded_sequence(embedded_padded, lengths, batch_first=True)
# lstm layer
output, _ = self.lstm(packed_output)
padded_output, lengths = pad_packed_sequence(output, batch_first=True)
# get hidden state of final non-padded sequence element:
h_n = []
for seq, length in zip(padded_output, lengths):
h_n.append(seq[length - 1, :])
lstm_out = torch.stack(h_n)
# linear layers
out = self.fc1(lstm_out)
return out
This morning, I ported my notebook over to an IDE and ran the debugger and confirmed that h_n is indeed the final hidden state of each sequence, not including padding.
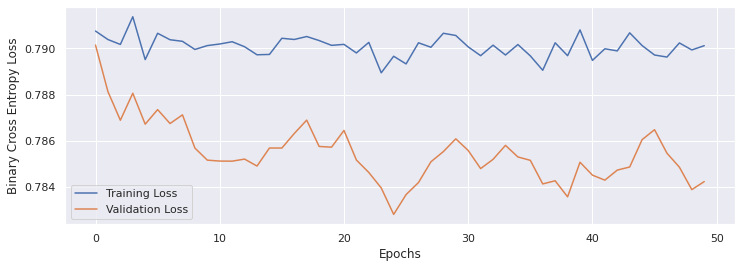
So everything runs/trains without error but my loss never decreases when I use batch size > 1.
With batch_size = 8:
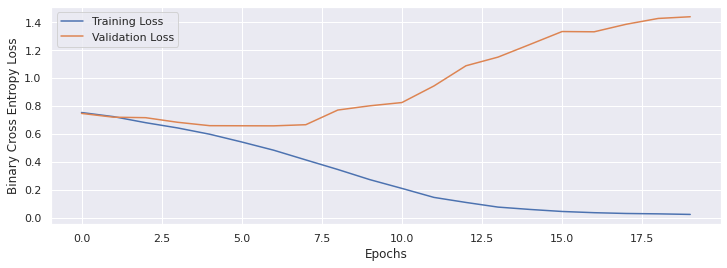
With `batch_size = 1:
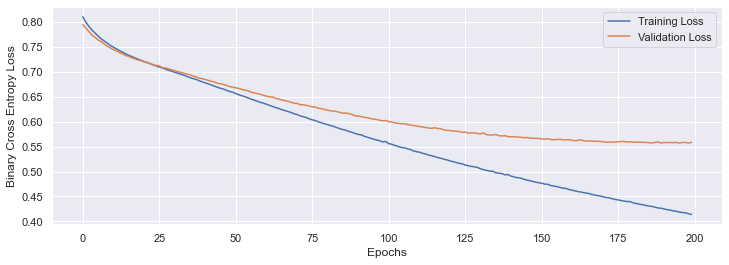
The reason I’m thinking I’ve done something wrong is that this performance is much worse than a simple embedding layer followed by a single linear layer:
self.embedding = nn.EmbeddingBag(vocab_size, embed_dim, sparse=True)
self.fc = nn.Linear(embed_dim, num_class)
Edit:
I thought I’d add the dataset, collate function and training code. This isn’t getting many hits, and I don’t know if that’s because my question is uninteresting or because I did’t provide enough data. So her’es more code:
Dataset:
class TextAndLabelsFromPandas(Dataset):
def __init__(self, dataframe):
self.dataframe = dataframe
self.n = 0
def __getitem__(self, idx):
text = pd.Series(self.dataframe.iloc[idx, :-1], dtype="string")
label = self.dataframe.iloc[idx, -1]
return label, " ".join(text.tolist())
def __len__(self):
return len(self.dataframe)
def __iter__(self):
return self;
def __next__(self):
if self.n < len(self):
result = self[self.n]
self.n += 1
return result
else:
raise StopIteration
Collate Function:
text_pipeline = lambda x: vocab(tokenizer(x))
def collate_batch(batch):
label_list, text_list = [], []
# Tokenize batch
for (label, text) in batch:
label_list.append(label)
processed_text = torch.tensor(text_pipeline(text), dtype=torch.int64)
text_list.append(processed_text)
# get lengths of individual sequences and sort by length
text_list.sort(key=lambda x: len(x), reverse=True)
lengths = [len(sequence) for sequence in text_list]
# convert to tensor and pad
label_tensor = torch.tensor(label_list, dtype=torch.float64)
padded_input_tensor = pad_sequence(text_list, batch_first=True, padding_value=vocab["<pad>"])
return label_tensor.to(device), padded_input_tensor.to(device), lengths
Training Protocol:
def train_one_epoch(model, opt, criterion, lr, trainloader):
model.to(device)
model.train()
running_tl = 0
for (label, sequence, lengths) in trainloader:
opt.zero_grad()
label = label.reshape(label.size()[0], 1)
output = model(sequence, lengths)
loss = criterion(output, label)
running_tl += loss.item()
loss.backward()
opt.step()
return running_tl
def validate_one_epoch(model, opt, criterion, lr, validloader):
running_vl = 0
model.eval()
with torch.no_grad():
for (label, sequence, lengths) in validloader:
label = label.reshape(label.shape[0], 1)
output = model(sequence, lengths)
loss = criterion(output, label)
running_vl += loss.item()
return running_vl
def train_model(model, opt, criterion, epochs, trainload, testload=None, lr=1e-3):
avg_tl_per_epoch = []
avg_vl_per_epoch = []
for e in trange(epochs):
running_tl = train_one_epoch(model, opt, criterion, lr, trainload)
avg_tl_per_epoch.append(running_tl / len(trainload))
if testload:
running_vl = validate_one_epoch(model, opt, criterion, lr, validloader)
avg_vl_per_epoch.append(running_vl / len(testload))
return avg_tl_per_epoch, avg_vl_per_epoch

