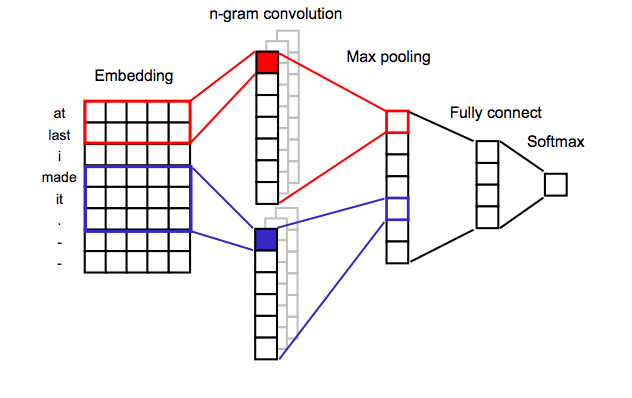
Again thank you so much for the code snippet. Actually, I was doing almost the as you did . Unlike you, I was using view rather than permute. I changed it to permute too. However I still doesn’t get the results explained in the paper.
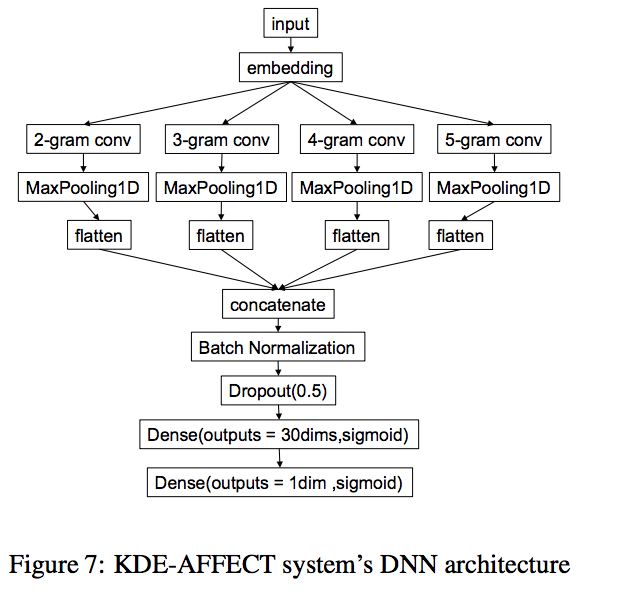
The arhitecture explain in the paper can be seen below. I believe that is exactly what I’ve implemented.
What could be wrong do you know any idea?
Below I again share my complete architecture:
class Anger2(nn.Module):
# out_channel: # output channel of convolutions (200 above I explained it as if 100 but actually it is 200)
# dense_out : 1st dense layer output dimension (30)
def __init__(self,embedding_matrix,out_channel,dense_out,n_gram_num):
super(Anger2, self).__init__()
num_embeddings,embedding_dim = embedding_matrix.shape
self.embedding = nn.Embedding(num_embeddings,embedding_dim)
self.embedding.weight = nn.Parameter(torch.tensor(embedding_matrix,dtype=torch.float))
self.conv2 = nn.Conv1d(embedding_dim,out_channel, kernel_size = 2)
self.conv3 = nn.Conv1d(embedding_dim,out_channel, kernel_size = 3)
self.conv4 = nn.Conv1d(embedding_dim,out_channel, kernel_size = 4)
self.conv5 = nn.Conv1d(embedding_dim,out_channel, kernel_size = 5)
self.conv6 = nn.Conv1d(embedding_dim,out_channel, kernel_size = 6)
# https://pytorch.org/docs/stable/nn.html#torch.nn.BatchNorm1d
self.dense1_bn = nn.BatchNorm1d(out_channel*n_gram_num)
self.drop = nn.Dropout(p=0.5)
self.fc1 = nn.Linear(out_channel*n_gram_num, dense_out)
self.sg1 = nn.Sigmoid()
self.fc2 = nn.Linear(dense_out, 1)
self.sg2 = nn.Sigmoid()
def forward(self,x):
# x shape: BSxMAX_LEN
embeds = self.embedding(x) # BS(64) x MAX_LEN(80) x EMBED_SIZE(200)
embeds = embeds.permute(0, 2, 1)
o2 = self.conv2(embeds) # 64,200,79
o2 = F.max_pool1d(o2,o2.shape[2])# 64,200,1
o2 = torch.squeeze(o2) # 64,200
o3 = self.conv3(embeds)
o3 = torch.squeeze(F.max_pool1d(o3,o3.shape[2]))
o4 = self.conv4(embeds)
o4 = torch.squeeze(F.max_pool1d(o4,o4.shape[2]))
o5 = self.conv5(embeds)
o5 = torch.squeeze(F.max_pool1d(o5,o5.shape[2]))
o6 = self.conv6(embeds)
o6 = torch.squeeze(F.max_pool1d(o6,o6.shape[2]))
concatenated = torch.cat((o2,o3,o4,o5,o6), 1) # 64x1000
concatenated = self.dense1_bn(concatenated)
out = self.drop(concatenated)
out = self.sg1(self.fc1(out))
out = self.sg2(self.fc2(out))
return out
# AND HERE IS TRAINING
EPOCH=30
BATCH_SIZE=64
loss_function = nn.MSELoss() # take sqrt to use it as RMSE
model = Anger2(embeddings,FILTER_NUMBER,DENSE_OUT,N_GRAM_NUM)
model.to(device)
#print(model)
optimizer = optim.Adam(model.parameters())
trn_batches = make_batch(trn,label_trn,is_shuffle=True)
dev_batches = make_batch(dev,label_dev,is_shuffle=True)
best_val = 1000.0
for epoch in range(EPOCH):
total_loss = 0.0
model.train()
for (trn_x,trn_y) in trn_batches:
model.zero_grad()
trn_x = trn_x.to(device)
trn_y = trn_y.to(device)
outs = model(trn_x)
loss = torch.sqrt(loss_function(outs,trn_y))
loss.backward()
optimizer.step()
total_loss += loss.item()
avg_trn_loss = total_loss/len(trn_batches)