I tried to implement ResNet 50 (doing Exercise 2 from d2l.ai book, section 7.6). You can find the ResNet 50 architecture described here (page 5, Table 1). However, when I train it, my train and test accuracies are 0.1 and training loss NaN. I’d really appreciate it if someone could have a look and see what may be the case here.
Here is my implementation, along with the debug output. I separate every code cell with its own code block. The outputs are also in their own code block.
Before I begin, a note: I worked through the shapes of the matrices on paper and the reason why I use self.conv4 and self.conv5 is so that I can adjust the network output and the input so that they can be added together. Maybe I should do all of this in some other way; I’m not sure. Please do have a look at the code below.
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
class Residual(nn.Module): #@save
"""The Residual block of ResNet."""
def __init__(self, input_channels, num_channels, strides=1):
# I removed the use_conv_1x1 attribute since I always adjust both X and Y
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels, kernel_size=1,
stride=strides)
self.conv2 = nn.Conv2d(num_channels, num_channels, kernel_size=3,
padding=1)
self.conv3 = nn.Conv2d(num_channels, num_channels * 4, kernel_size=1) # no padding doesn't change the
# image shape
self.conv4 = nn.Conv2d(num_channels*4, num_channels,
kernel_size=1) # used to adjust Y
self.conv5 = nn.Conv2d(input_channels, num_channels,
kernel_size=1, stride=strides) # used to adjust X
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
self.bn3 = nn.BatchNorm2d(num_channels * 4)
def forward(self, X):
# debug purpose prints are commented out
print("-----------------------------------")
print("X.shape:")
print(X.shape)
Y = F.relu(self.bn1(self.conv1(X)))
print("Y.shape:")
print(Y.shape)
Y = F.relu(self.bn2(self.conv2(Y)))
print("Y.shape:")
print(Y.shape)
Y = F.relu(self.bn3(self.conv3(Y)))
print("Y.shape:")
print(Y.shape)
Y = self.conv4(Y)
print("Y.shape:")
print(Y.shape)
print("X.shape:")
print(X.shape)
X = self.conv5(X)
print("X.shape:")
print(X.shape)
print("-----------------------------------")
Y += X
return F.relu(Y)
blk = Residual(3, 3)
X = torch.rand(4, 3, 6, 6)
Y = blk(X)
Y.shape
-----------------------------------
X.shape:
torch.Size([4, 3, 6, 6])
Y.shape:
torch.Size([4, 3, 6, 6])
Y.shape:
torch.Size([4, 3, 6, 6])
Y.shape:
torch.Size([4, 12, 6, 6])
Y.shape:
torch.Size([4, 3, 6, 6])
X.shape:
torch.Size([4, 3, 6, 6])
X.shape:
torch.Size([4, 3, 6, 6])
-----------------------------------
torch.Size([4, 3, 6, 6])
blk = Residual(3, 6, strides=2)
blk(X).shape
-----------------------------------
X.shape:
torch.Size([4, 3, 6, 6])
Y.shape:
torch.Size([4, 6, 3, 3])
Y.shape:
torch.Size([4, 6, 3, 3])
Y.shape:
torch.Size([4, 24, 3, 3])
Y.shape:
torch.Size([4, 6, 3, 3])
X.shape:
torch.Size([4, 3, 6, 6])
X.shape:
torch.Size([4, 6, 3, 3])
-----------------------------------
torch.Size([4, 6, 3, 3])
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
def resnet_block(input_channels, num_channels, num_residuals,
first_block=False):
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(
Residual(input_channels, num_channels,
strides=2))
else:
blk.append(Residual(num_channels, num_channels))
return blk
b2 = nn.Sequential(*resnet_block(64, 64, 3, first_block=True))
b3 = nn.Sequential(*resnet_block(64, 128, 4))
b4 = nn.Sequential(*resnet_block(128, 256, 6))
b5 = nn.Sequential(*resnet_block(256, 512, 3))
net = nn.Sequential(b1, b2, b3, b4, b5, nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(), nn.Linear(512, 10))
X = torch.rand(size=(1, 1, 224, 224))
for layer in net:
print("X.shape:")
print(X.shape)
X = layer(X)
print(layer.__class__.__name__, 'output shape:\t', X.shape)
X.shape:
torch.Size([1, 1, 224, 224])
Sequential output shape: torch.Size([1, 64, 56, 56])
X.shape:
torch.Size([1, 64, 56, 56])
-----------------------------------
X.shape:
torch.Size([1, 64, 56, 56])
Y.shape:
torch.Size([1, 64, 56, 56])
Y.shape:
torch.Size([1, 64, 56, 56])
Y.shape:
torch.Size([1, 256, 56, 56])
Y.shape:
torch.Size([1, 64, 56, 56])
X.shape:
torch.Size([1, 64, 56, 56])
X.shape:
torch.Size([1, 64, 56, 56])
-----------------------------------
-----------------------------------
X.shape:
torch.Size([1, 64, 56, 56])
Y.shape:
torch.Size([1, 64, 56, 56])
Y.shape:
torch.Size([1, 64, 56, 56])
Y.shape:
torch.Size([1, 256, 56, 56])
Y.shape:
torch.Size([1, 64, 56, 56])
X.shape:
torch.Size([1, 64, 56, 56])
X.shape:
torch.Size([1, 64, 56, 56])
-----------------------------------
-----------------------------------
X.shape:
torch.Size([1, 64, 56, 56])
Y.shape:
torch.Size([1, 64, 56, 56])
Y.shape:
torch.Size([1, 64, 56, 56])
Y.shape:
torch.Size([1, 256, 56, 56])
Y.shape:
torch.Size([1, 64, 56, 56])
X.shape:
torch.Size([1, 64, 56, 56])
X.shape:
torch.Size([1, 64, 56, 56])
-----------------------------------
Sequential output shape: torch.Size([1, 64, 56, 56])
X.shape:
torch.Size([1, 64, 56, 56])
-----------------------------------
X.shape:
torch.Size([1, 64, 56, 56])
Y.shape:
torch.Size([1, 128, 28, 28])
Y.shape:
torch.Size([1, 128, 28, 28])
Y.shape:
torch.Size([1, 512, 28, 28])
Y.shape:
torch.Size([1, 128, 28, 28])
X.shape:
torch.Size([1, 64, 56, 56])
X.shape:
torch.Size([1, 128, 28, 28])
-----------------------------------
-----------------------------------
X.shape:
torch.Size([1, 128, 28, 28])
Y.shape:
torch.Size([1, 128, 28, 28])
Y.shape:
torch.Size([1, 128, 28, 28])
Y.shape:
torch.Size([1, 512, 28, 28])
Y.shape:
torch.Size([1, 128, 28, 28])
X.shape:
torch.Size([1, 128, 28, 28])
X.shape:
torch.Size([1, 128, 28, 28])
-----------------------------------
-----------------------------------
X.shape:
torch.Size([1, 128, 28, 28])
Y.shape:
torch.Size([1, 128, 28, 28])
Y.shape:
torch.Size([1, 128, 28, 28])
Y.shape:
torch.Size([1, 512, 28, 28])
Y.shape:
torch.Size([1, 128, 28, 28])
X.shape:
torch.Size([1, 128, 28, 28])
X.shape:
torch.Size([1, 128, 28, 28])
-----------------------------------
-----------------------------------
X.shape:
torch.Size([1, 128, 28, 28])
Y.shape:
torch.Size([1, 128, 28, 28])
Y.shape:
torch.Size([1, 128, 28, 28])
Y.shape:
torch.Size([1, 512, 28, 28])
Y.shape:
torch.Size([1, 128, 28, 28])
X.shape:
torch.Size([1, 128, 28, 28])
X.shape:
torch.Size([1, 128, 28, 28])
-----------------------------------
Sequential output shape: torch.Size([1, 128, 28, 28])
X.shape:
torch.Size([1, 128, 28, 28])
-----------------------------------
X.shape:
torch.Size([1, 128, 28, 28])
Y.shape:
torch.Size([1, 256, 14, 14])
Y.shape:
torch.Size([1, 256, 14, 14])
Y.shape:
torch.Size([1, 1024, 14, 14])
Y.shape:
torch.Size([1, 256, 14, 14])
X.shape:
torch.Size([1, 128, 28, 28])
X.shape:
torch.Size([1, 256, 14, 14])
-----------------------------------
-----------------------------------
X.shape:
torch.Size([1, 256, 14, 14])
Y.shape:
torch.Size([1, 256, 14, 14])
Y.shape:
torch.Size([1, 256, 14, 14])
Y.shape:
torch.Size([1, 1024, 14, 14])
Y.shape:
torch.Size([1, 256, 14, 14])
X.shape:
torch.Size([1, 256, 14, 14])
X.shape:
torch.Size([1, 256, 14, 14])
-----------------------------------
-----------------------------------
X.shape:
torch.Size([1, 256, 14, 14])
Y.shape:
torch.Size([1, 256, 14, 14])
Y.shape:
torch.Size([1, 256, 14, 14])
Y.shape:
torch.Size([1, 1024, 14, 14])
Y.shape:
torch.Size([1, 256, 14, 14])
X.shape:
torch.Size([1, 256, 14, 14])
X.shape:
torch.Size([1, 256, 14, 14])
-----------------------------------
-----------------------------------
X.shape:
torch.Size([1, 256, 14, 14])
Y.shape:
torch.Size([1, 256, 14, 14])
Y.shape:
torch.Size([1, 256, 14, 14])
Y.shape:
torch.Size([1, 1024, 14, 14])
Y.shape:
torch.Size([1, 256, 14, 14])
X.shape:
torch.Size([1, 256, 14, 14])
X.shape:
torch.Size([1, 256, 14, 14])
-----------------------------------
-----------------------------------
X.shape:
torch.Size([1, 256, 14, 14])
Y.shape:
torch.Size([1, 256, 14, 14])
Y.shape:
torch.Size([1, 256, 14, 14])
Y.shape:
torch.Size([1, 1024, 14, 14])
Y.shape:
torch.Size([1, 256, 14, 14])
X.shape:
torch.Size([1, 256, 14, 14])
X.shape:
torch.Size([1, 256, 14, 14])
-----------------------------------
-----------------------------------
X.shape:
torch.Size([1, 256, 14, 14])
Y.shape:
torch.Size([1, 256, 14, 14])
Y.shape:
torch.Size([1, 256, 14, 14])
Y.shape:
torch.Size([1, 1024, 14, 14])
Y.shape:
torch.Size([1, 256, 14, 14])
X.shape:
torch.Size([1, 256, 14, 14])
X.shape:
torch.Size([1, 256, 14, 14])
-----------------------------------
Sequential output shape: torch.Size([1, 256, 14, 14])
X.shape:
torch.Size([1, 256, 14, 14])
-----------------------------------
X.shape:
torch.Size([1, 256, 14, 14])
Y.shape:
torch.Size([1, 512, 7, 7])
Y.shape:
torch.Size([1, 512, 7, 7])
Y.shape:
torch.Size([1, 2048, 7, 7])
Y.shape:
torch.Size([1, 512, 7, 7])
X.shape:
torch.Size([1, 256, 14, 14])
X.shape:
torch.Size([1, 512, 7, 7])
-----------------------------------
-----------------------------------
X.shape:
torch.Size([1, 512, 7, 7])
Y.shape:
torch.Size([1, 512, 7, 7])
Y.shape:
torch.Size([1, 512, 7, 7])
Y.shape:
torch.Size([1, 2048, 7, 7])
Y.shape:
torch.Size([1, 512, 7, 7])
X.shape:
torch.Size([1, 512, 7, 7])
X.shape:
torch.Size([1, 512, 7, 7])
-----------------------------------
-----------------------------------
X.shape:
torch.Size([1, 512, 7, 7])
Y.shape:
torch.Size([1, 512, 7, 7])
Y.shape:
torch.Size([1, 512, 7, 7])
Y.shape:
torch.Size([1, 2048, 7, 7])
Y.shape:
torch.Size([1, 512, 7, 7])
X.shape:
torch.Size([1, 512, 7, 7])
X.shape:
torch.Size([1, 512, 7, 7])
-----------------------------------
Sequential output shape: torch.Size([1, 512, 7, 7])
X.shape:
torch.Size([1, 512, 7, 7])
AdaptiveAvgPool2d output shape: torch.Size([1, 512, 1, 1])
X.shape:
torch.Size([1, 512, 1, 1])
Flatten output shape: torch.Size([1, 512])
X.shape:
torch.Size([1, 512])
Linear output shape: torch.Size([1, 10])
The training code (from the book; not modified by me) is:
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):
"""Train a model with a GPU (defined in Chapter 6)."""
net.initialize(force_reinit=True, ctx=device, init=init.Xavier())
loss = gluon.loss.SoftmaxCrossEntropyLoss()
trainer = gluon.Trainer(net.collect_params(), 'sgd',
{'learning_rate': lr})
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=['train loss', 'train acc', 'test acc'])
timer, num_batches = d2l.Timer(), len(train_iter)
for epoch in range(num_epochs):
# Sum of training loss, sum of training accuracy, no. of examples
metric = d2l.Accumulator(3)
for i, (X, y) in enumerate(train_iter):
timer.start()
# Here is the major difference from `d2l.train_epoch_ch3`
X, y = X.as_in_ctx(device), y.as_in_ctx(device)
with autograd.record():
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
trainer.step(X.shape[0])
metric.add(l.sum(), d2l.accuracy(y_hat, y), X.shape[0])
timer.stop()
train_l = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(train_l, train_acc, None))
test_acc = evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, '
f'test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec '
f'on {str(device)}')
with evaluate_accuracy_gpu being defined as follows:
def evaluate_accuracy_gpu(net, data_iter, device=None): #@save
"""Compute the accuracy for a model on a dataset using a GPU."""
if not device: # Query the first device where the first parameter is on
device = list(net.collect_params().values())[0].list_ctx()[0]
# No. of correct predictions, no. of predictions
metric = d2l.Accumulator(2)
for X, y in data_iter:
X, y = X.as_in_ctx(device), y.as_in_ctx(device)
metric.add(d2l.accuracy(net(X), y), y.size)
return metric[0] / metric[1]
Here is the training graph:
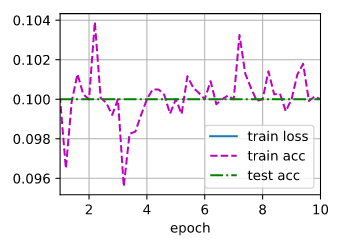
Some additional information:
The dataset is fashion MNIST. Training loss is NaN after 10 epochs. I don’t measure the test loss. I used a function for loading the fashion MNIST dataset into memory from the Dive into Deep Learning book and I believe it keeps the same distribution of classes as in the dataset (it is stratified).
Do you see what is the issue?
Thank you in advance!