Hello, torch.Size([64, 3, 224, 224])
I am new to pytorch, and have been using it for a school project. My overall goal for the project is to build a resnet50 to identify the images in imagenet. I went through some tutorials and built a simple resnet for analysing the MNIST dataset, but now that I have moved to a more complicated resnet, my training accuracy and loss are stuck near 0 and I am not sure why.
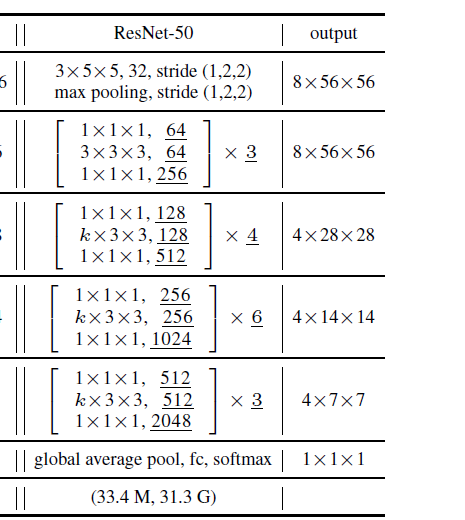
I have tried varying the momentum from 0.9 to 0.1 and learning rate from 0.001 to sqrt(0.1) but I still am unable to train my model. I suspect my dataloader is incorrect, as the dimensions on my xb variable in my training loop are [64, 3, 224, 224] which is different from the [64, 784] dimensional input I saw when training on MNIST but I am not sure. Any help with this would be greatly appreciated. I have inserted my code and a clip of the structure of the resnet my project is trying to emulate. The resnet in the image is for a video classifier, but we were told to just modify it so it worked for image analysis by removing the time dimension. Thank you in advance for your help.
import torch
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
from torch import optim
from torch.utils.data import TensorDataset
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
import torchvision.datasets as datasets
from torch.utils.data import TensorDataset
import torch.utils.data as data
from datetime import datetime
import math
import torchvision
import time
initialOutputSize = 56
block1Size = 32
convBlock2Size = 64
convBlock3Size = 128
convBlock4Size = 256
convBlock5Size = 512
def outSizeCalculator(inSize, padding, kernelSize, stride):
return floor((inSize+2*padding - kernelSize)/stride + 1)
class InitialConvblock(nn.Module):
def __init__(self, in_size, out_size): #In size of 224, outsize of 56
super().__init__()
self.kernelSize = 5
self.stride = 2
self.pad = 2
self.conv1 = nn.Conv2d(in_size, out_size, self.kernelSize, self.stride, self.pad)
self.batchnorm1 = nn.BatchNorm2d(out_size)
self.maxpool = nn.AdaptiveMaxPool2d(initialOutputSize)
def InitialConvblock(self, x):
x = self.maxpool(F.relu(self.batchnorm1(self.conv1(x))))
return x
def forward(self, x): return self.InitialConvblock(x)
class ResBlock(nn.Module):
def __init__(self, in_size, hidden_layer_size, out_size, cutSize=False):
super().__init__()
self.kernelSize1 = 1
self.kernelSize3 = 3
self.stride1 = 1
self.stride2 = 2
if cutSize:
self.initialStride=2
else:
self.initialStride=1
self.pad0 = 0
self.pad1 = 1
self.conv1 = nn.Conv2d(in_size, hidden_layer_size, self.kernelSize1, self.initialStride, self.pad0)
self.conv2 = nn.Conv2d(hidden_layer_size, hidden_layer_size, self.kernelSize3, self.stride1, self.pad0)
self.conv3 = nn.Conv2d(hidden_layer_size, out_size, self.kernelSize1, self.stride1, self.pad1)
self.convShortcut = nn.Conv2d(in_size, out_size, self.kernelSize1, self.stride1, self.pad0)
self.convShortcutResize = nn.Conv2d(in_size, out_size, self.kernelSize1, self.stride2, self.pad0) #Use if Final shortcut for block
self.batchnorm1 = nn.BatchNorm2d(hidden_layer_size)
self.batchnorm2 = nn.BatchNorm2d(out_size)
def resblock(self, x, resizeShortcut=False):
if resizeShortcut:
shortcut = self.convShortcutResize(x)
else:
shortcut = self.convShortcut(x)
blockOutput = F.relu(self.batchnorm2(self.conv3(F.relu(self.batchnorm1(self.conv2(F.relu(self.batchnorm1(self.conv1(x)))))))))
return shortcut + blockOutput
def forward(self, x, resizeShortcut=False): return self.resblock(x, resizeShortcut)
class ResNet(nn.Module):
def __init__(self, n_classes=1000):
super().__init__()
self.nClasses = n_classes
self.convBlock1 = InitialConvblock(numChannels, block1Size)
self.block2a = ResBlock(block1Size, convBlock2Size, convBlock2Size*4)
self.block2b = ResBlock(convBlock2Size*4, convBlock2Size,convBlock2Size*4)
self.block3a = ResBlock(convBlock3Size*2, convBlock3Size, convBlock3Size*4, True)
self.block3b = ResBlock(convBlock3Size*4, convBlock3Size, convBlock3Size*4)
self.block4a = ResBlock(convBlock4Size*2, convBlock4Size, convBlock4Size*4, True)
self.block4b = ResBlock(convBlock4Size*4, convBlock4Size, convBlock4Size*4)
self.block5a = ResBlock(convBlock5Size*2, convBlock5Size, convBlock5Size*4, True)
self.block5b = ResBlock(convBlock5Size*4, convBlock5Size, convBlock5Size*4)
self.globalAvgPool = nn.AvgPool2d(kernel_size=7, stride=1)
self.linearLayer = nn.Linear(2048, self.nClasses) #num classes
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
x = self.convBlock1(x)
x = self.block2b(self.block2b(self.block2a(x)))
x = self.block3b(self.block3b(self.block3b(self.block3a(x, True))))
x = self.block4b(self.block4b(self.block4b(self.block4b(self.block4b(self.block4a(x, True))))))
x = self.block5b(self.block5b(self.block5a(x, True)))
x = self.globalAvgPool(x)
x = x.view(-1, 2048)
x = F.relu(self.linearLayer(x))
x = self.softmax(x)
return x
def loss_batch(model, loss_func, xb, yb, opt=None, scheduler=None):
loss = loss_func(model(xb), yb.long())
acc = accuracy(model(xb), yb)
print("Batch Loss: ", loss.item())
print("Batch Accuracy: ", acc.item())
if opt is not None:
loss.backward()
if scheduler is not None:
scheduler.step()
opt.step()
opt.zero_grad()
return acc, loss.item(), len(xb)
def accuracy(out, yb):
preds = torch.argmax(out, dim=1)
return (preds == yb).float().mean() #Need to convert to float for mean to work
def train_model(epochs, model, loss_func, opt, train_dl, test_dl, device, savePath, scheduler=None):
for epoch in range(epochs):
now = datetime.now()
current_time = now.strftime("%H:%M:%S")
print("Beginning Epoch at ", current_time)
model.train()
i = 0
running_loss = 0
displayInterval = 50
for xb, yb, in train_dl: #xb and yb could be wrong size?
#print(xb.size())
#print(yb.size())
xb = xb.to(device)
yb = yb.to(device)
loss, acc, num = loss_batch(model, loss_func, xb, yb, opt, scheduler)
running_loss += loss
if i % displayInterval == displayInterval - 1:
print("Batch Number: ", i)
currLoss = running_loss/displayInterval
print("Running Loss: ", currLoss)
running_loss = 0
i += 1
print("Evaluating Model")
model.eval()
#No gradient computation for evaluation mode
with torch.no_grad():
accs = []
losses = []
nums = []
for xb, yb in test_dl:
acc, loss, num = loss_batch(model, loss_func, xb.to(device), yb.to(device))
accs.append(acc)
losses.append(loss)
nums.append(num)
val_loss = np.sum(np.multiply(losses, nums)) / np.sum(nums)
val_acc = np.sum(np.multiply(accs, nums)) / np.sum(nums)
print("Epoch:", epoch+1)
print("Loss: ", val_loss)
print("Accuracy: ", val_acc)
torch.save(model.state_dict(), savePath)
def get_train_dataset(dir):
imageSize = 224
trainTransforms = transforms.Compose([
transforms.RandomResizedCrop(imageSize),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.455, 0.405], std=[0.229, 0.224, 0.225]) #Check if std deviation should be set
])
trainDataset = datasets.ImageFolder(dir, trainTransforms)
return trainDataset
def get_val_dataset(dir):
valTransforms = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.455, 0.405], std=[0.229, 0.224, 0.225]) #Check if std deviation should be set
])
valDataset = datasets.ImageFolder(dir, valTransforms)
return valDataset
def getDataloaders(dataDir, valDir, batchSize, workers=0, pin_memory=False): #Can also add pin_memory
trainDataset = get_train_dataset(dataDir)
valDataset = get_val_dataset(valDir)
trainLoader = torch.utils.data.DataLoader(trainDataset, batch_size = batchSize, shuffle=True, num_workers=workers, pin_memory=pin_memory, sampler=None)
valLoader = torch.utils.data.DataLoader(valDataset, batch_size = batchSize, shuffle=False, num_workers=workers, pin_memory=pin_memory)
return trainLoader, valLoader
#Hyperparameters
bs = 64 #Max batch size is 128
lr = math.sqrt(0.1)
n_epochs = 2
loss_func = F.cross_entropy
numChannels = 3
numClasses = 200
outputFile = '/home/mcvi0001/A^2_Net_Code/Imagenet_resnet.pth'
trainDir = "/home/mcvi0001/A^2_Net_Code/tiny-imagenet-200/train"
testDir = "/home/mcvi0001/A^2_Net_Code/tiny-imagenet-200/test"
valDir = "/home/mcvi0001/A^2_Net_Code/tiny-imagenet-200/val"
print(torch.cuda.get_device_name(0))
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
trainDL, testDL = getDataloaders(trainDir, testDir, bs)
#Model/optimizer
model = ResNet(numClasses)
optimizer = optim.SGD(model.parameters(), lr=lr, momentum=0.9)
if torch.cuda.device_count() > 1:
print("Let's use", torch.cuda.device_count(), "GPUs!")
model = nn.DataParallel(model)
model.to(device)
#train
train_model(n_epochs, model, loss_func, optimizer, trainDL, testDL, device, outputFile)
now = datetime.now()
current_time = now.strftime("%H:%M:%S")
print("Finished Training at", current_time)
torch.save(model.state_dict(), outputFile)
print("Finished Saving")