class BasicBlock(nn.Module):
def __init__(self, in_planes, out_planes, stride, dropRate=0.0):
super(BasicBlock, self).__init__()
self.bn1 = nn.BatchNorm2d(in_planes)
self.relu1 = nn.ReLU(inplace=True)
self.conv1 = nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1, bias=False) # 1
self.bn2 = nn.BatchNorm2d(out_planes)
self.relu2 = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(out_planes, out_planes, kernel_size=3, stride=1,
padding=1, bias=False)
self.droprate = dropRate
self.equalInOut = (in_planes == out_planes)
self.convShortcut = (not self.equalInOut) and nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride,
padding=0, bias=False) or None
def forward(self, x):
if not self.equalInOut:
x = self.relu1(self.bn1(x))
else:
out = self.relu1(self.bn1(x))
out = self.relu2(self.bn2(self.conv1(out if self.equalInOut else x)))
if self.droprate > 0:
out = F.dropout(out, p=self.droprate, training=self.training)
out = self.conv2(out)
if self.convShortcut is not None:
return torch.add(x if self.equalInOut else self.convShortcut(x), out)
class NetworkBlock(nn.Module):
def __init__(self, nb_layers, in_planes, out_planes, block, stride, dropRate=0.0):
super(NetworkBlock, self).__init__()
self.layer = self._make_layer(block, in_planes, out_planes, nb_layers, stride, dropRate)
def _make_layer(self, block, in_planes, out_planes, nb_layers, stride, dropRate):
layers = []
for i in range(int(nb_layers)):
layers.append(block(i == 0 and in_planes or out_planes, out_planes, i == 0 and stride or 1, dropRate))
return nn.Sequential(*layers)
def forward(self, x):
return self.layer(x)
class WideResNet(nn.Module):
def __init__(self, depth=34, num_classes=10, widen_factor=10, dropRate=0.0):
super(WideResNet, self).__init__()
nChannels = [16, 16 * widen_factor, 32 * widen_factor, 64 * widen_factor]
assert ((depth - 4) % 6 == 0)
n = (depth - 4) / 6
block = BasicBlock
# 1st conv before any network block
self.conv1 = nn.Conv2d(3, nChannels[0], kernel_size=3, stride=1,
padding=1, bias=False)
# 1st block
self.block1 = NetworkBlock(n, nChannels[0], nChannels[1], block, 1, dropRate)
# 1st sub-block
self.sub_block1 = NetworkBlock(n, nChannels[0], nChannels[1], block, 1, dropRate)
# 2nd block
self.block2 = NetworkBlock(n, nChannels[1], nChannels[2], block, 2, dropRate) # 2
# 3rd block
self.block3 = NetworkBlock(n, nChannels[2], nChannels[3], block, 2, dropRate) # 2
# global average pooling and classifier
self.bn1 = nn.BatchNorm2d(nChannels[3])
self.relu = nn.ReLU(inplace=True)
self.fc = nn.Linear(nChannels[3], num_classes)
self.nChannels = nChannels[3]
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
m.bias.data.zero_()
def forward(self, x):
out = self.conv1(x)
out = self.block1(out)
out = self.block2(out)
out = self.block3(out)
out = self.relu(self.bn1(out))
out = F.avg_pool2d(out, 8)
out = out.view(-1, self.nChannels)
return self.fc(out)
def _conv(self, name, x, filter_size, in_filters, out_filters, strides, padding='SAME'):
"""Convolution."""
with tf.variable_scope(name):
n = filter_size * filter_size * out_filters
kernel = tf.get_variable(
'DW', [filter_size, filter_size, in_filters, out_filters],
tf.float32, initializer=tf.random_normal_initializer(
stddev=np.sqrt(2.0/n)))
return tf.nn.conv2d(x, kernel, strides, padding=padding)
def _residual(self, x, in_filter, out_filter, stride,
activate_before_residual=False, is_log=False):
"""Residual unit with 2 sub layers."""
if activate_before_residual:
x = self._batch_norm('bn1', x)
x = self._relu(x)
orig_x = x
else:
orig_x = x
x = self._batch_norm('bn1', x)
x = self._relu(x)
x = self._conv('conv1', x, 3, in_filter, out_filter, stride)
x = self._batch_norm('bn2', x)
x = self._relu(x)
x = self._conv('conv2', x, 3, out_filter, out_filter, [1, 1, 1, 1])
if in_filter != out_filter:
orig_x = self._conv('shortcut_conv', orig_x, filter_size=1, in_filters=in_filter, out_filters=out_filter,
strides=stride, padding="VALID")
x += orig_x
return x
def _build_model(self):
assert self.mode == 'train' or self.mode == 'eval'
with tf.variable_scope('input'):
self.x_input = tf.placeholder(tf.float32, shape=[None, 32, 32, 3])
self.y_input = tf.placeholder(tf.float32, shape=[None, 10])
self.is_training = tf.placeholder(tf.bool, shape=None)
x = self._conv('conv1.weight', self.x_input, 3, 3, 16, self._stride_arr(1))
strides = [1, 2, 2]
activate_before_residual = [True, True, True]
res_func = self._residual
# wide residual network (https://arxiv.org/abs/1605.07146v1)
filters = [16, 160, 320, 640]
with tf.variable_scope('block1.layer.0'):
x = res_func(x, filters[0], filters[1], self._stride_arr(strides[0]),
activate_before_residual[0])
for i in range(1, 5):
with tf.variable_scope('block1.layer.%d' % i):
x = res_func(x, filters[1], filters[1], self._stride_arr(1), False)
with tf.variable_scope('block2.layer.0'):
x = res_func(x, filters[1], filters[2], self._stride_arr(strides[1]),
activate_before_residual[1], is_log=True)
for i in range(1, 5):
with tf.variable_scope('block2.layer.%d' % i):
x = res_func(x, filters[2], filters[2], self._stride_arr(1), False)
with tf.variable_scope('block3.layer.0'):
x = res_func(x, filters[2], filters[3], self._stride_arr(strides[2]),
activate_before_residual[2])
for i in range(1, 5):
with tf.variable_scope('block3.layer.%d' % i):
x = res_func(x, filters[3], filters[3], self._stride_arr(1), False)
x = self._batch_norm('bn1', x)
x = self._relu(x)
x = self._global_avg_pool(x)
with tf.variable_scope('fc'):
self.pre_softmax = self._fully_connected(x, 10)
I’m doing experiment on “adversarial defense”, and I checked that the performances of pytorch and tensorflow is different with same weights (I exported it as numpy and loaded to pytorch and tensorflow) I printed out each result of WideResNet34 and calculate the difference of each output, then, the above output of below image comes out
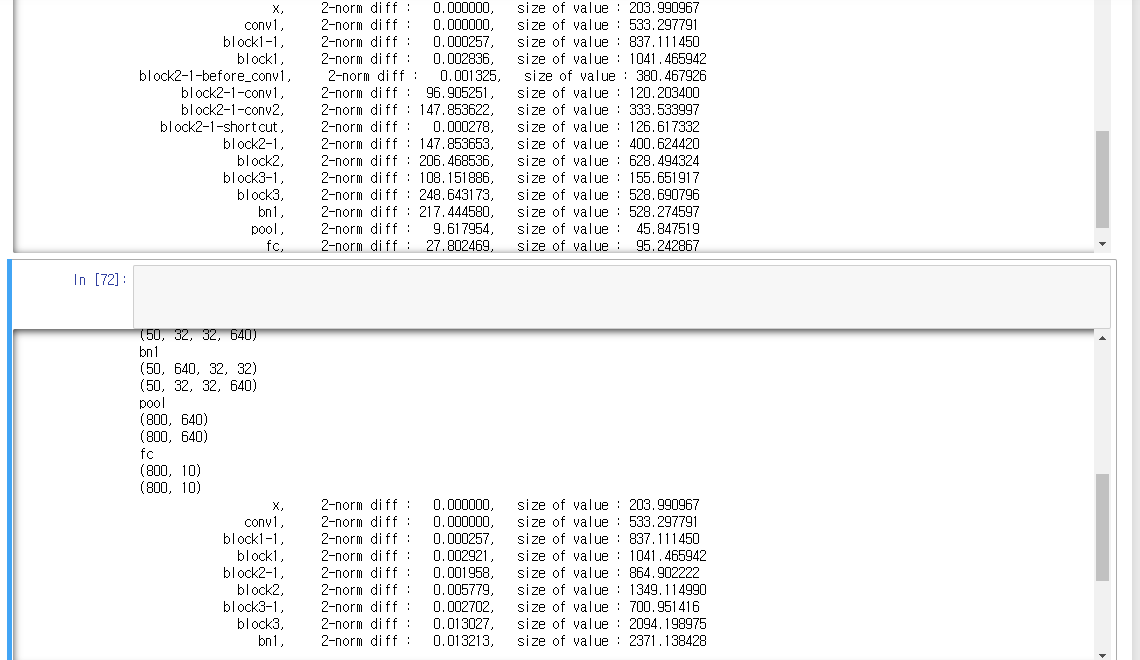
The results start to be different from block2. Then, I only change the stride of each block to all 1 (stride of block 2 and 3), the below output of above image comes out
The differences are negligible at all layers, so I think the difference appear only when stride=2. I don’t know why there is no difference when stride=1 but different when stride=2… Who knows about this thing?