ptrblck
January 11, 2020, 3:29am
21
Thanks for the scripts and the effort writing them!
Could you give me some more information on the workflow?
Created synthetic data using pz_synth_data.py. (I lowered the data size to 128*10**2, 128*10**2, and 10*10**2)
executed pz_train_resnet.py to train the model and store checkpoints
run pz_debug_bn.py
and get an error of: max abs error: 1.9073486328125e-06, which points to floating point precision limits.
I have just skimmed through the code as it’s quite long, but should the large error be reproducible with these steps or am I missing something?
Dear @ptrblck thanks for your interest.
Well, I think you’ve figured out the workflow. Now, the discussion can be more precise
when you run pz_debug_bn.py you load the model state as well as the test inputs and the corresponding output obtaining during the training (ie pz_train_resnet.py). As myself the max abs err is about 1e-6 and is ok, notice however that is you train the simple convolutional network ( see option of ``pz_train_resnet.py) than the result is 0.0`. But as we have discussed together earlier it may be due the cuda backend parameters.
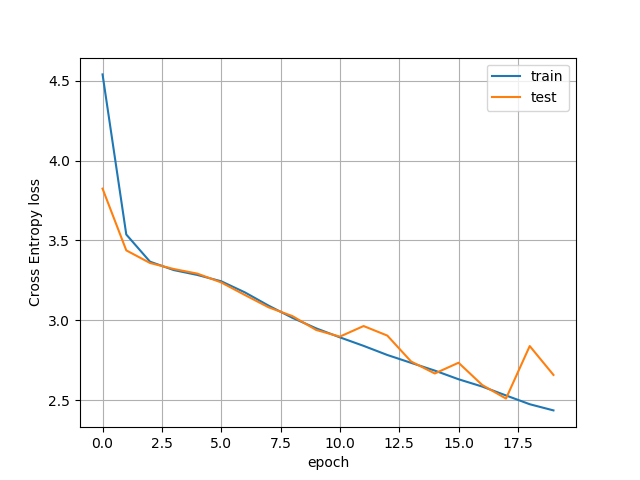
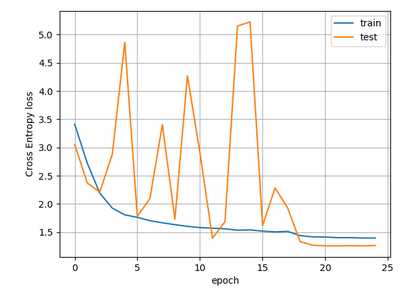
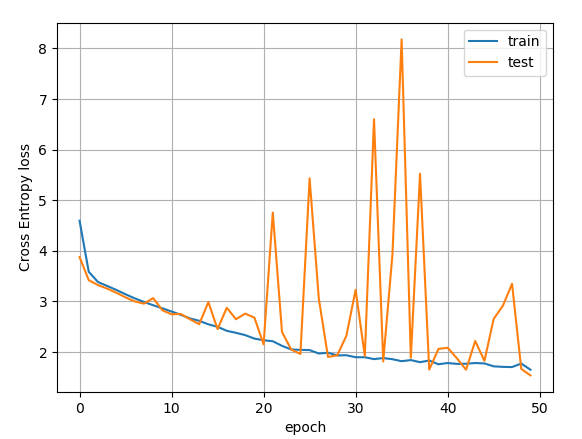
Now, my real problem that can be reproduced is the hieratic behaviour of the test loss during the training. By the way it is the original problem that have motivated this thread. You can see it if you display the curves of the train & test losses thanks to history.py script applied to the nty file which is an output of the pz_train_resnet.pyscript. You do it as follows : python history.py --file <file.nty> --tag <what-u-want>.
Let me know what do you obtain. Thanks.
@ptrblck thanks for your interest. My problem is of course not at the level of 1e-6, here is
fake_data = False,
use_weighted_class = False, # to reweight the class
weights_file = './synth_weight.npy',
network = "resnet20", # alternative : "resnet20" or "convnet"
deterministic = False, # torch.backends.cudnn.deterministic
benchmark = True, # torch.backends.cudnn.benchmark
data_augmentation = True, # use or not data augmentation
If you do not reproduce this curve then the problem is elsewhere (nb. I’ve generate 128k train/128k test and 10k valid.)
ptrblck
January 18, 2020, 3:08pm
26
To my understanding the code reproduces the difference of approx. 1e-6.
Hello @ptrblck , Thanks for your interest.pz_train_resnet.pywith
fake_data = False, # True means random inputs, False means either REAL or SYNTHISED data
use_weighted_class = False, # to reweight the class
weights_file = './weights_real.npy',
network = "resnet20", # alternative : "resnet20" or "convnet"
deterministic = False, # torch.backends.cudnn.deterministic
benchmark = True, # torch.backends.cudnn.benchmark
data_augmentation = True, # use or not data augmentation
and got SYNTHETIZED DATA (128k train and 128k test )
Can you try to reproduce it?
Now I f I use REAL data
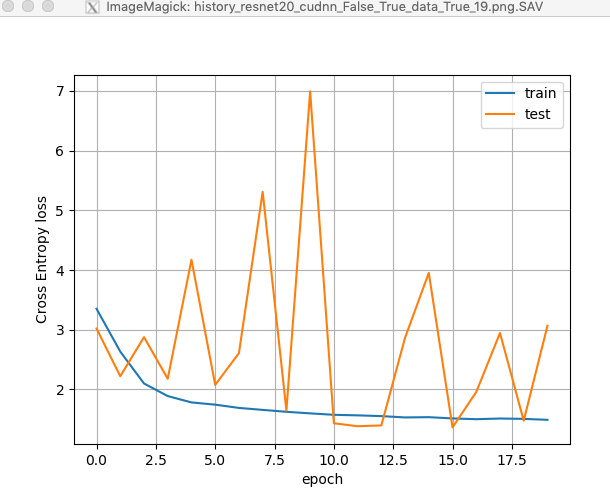
So, in both case the Test Loss has a hieratic behaviour.
ptrblck
January 26, 2020, 4:16am
28
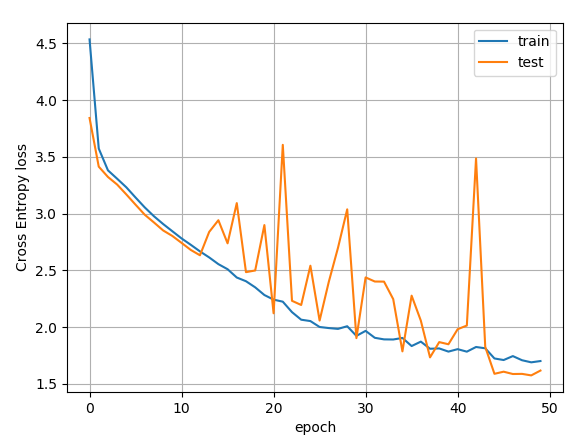
I tried to rerun pz_train_resnet.py with your arguments and afterwards pz_debug_bn.py, which yields a max absolute error of 1e-6 again.
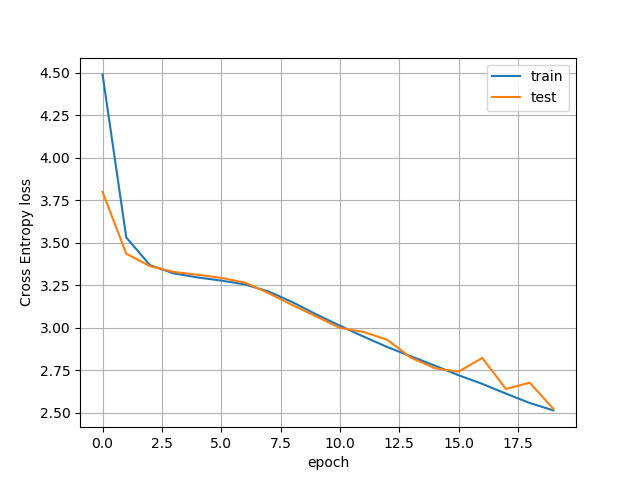
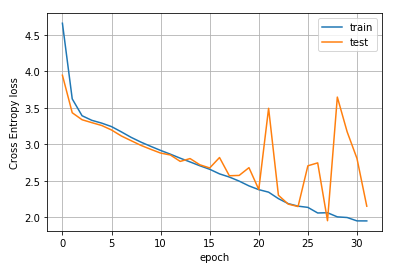
This is the plot for 19 epochs:
HI @ptrblck Thanks for your interest
So, if I understand correctly your loss plot has been obtained during the training with the synthetized data. So it should be compared to the one I got (copied from the plot of the previous post)
So we have to focus on what could be wrong during the training on my side. When you have run the pz_train_resnet.py script can you tell what parameters you have used, please?
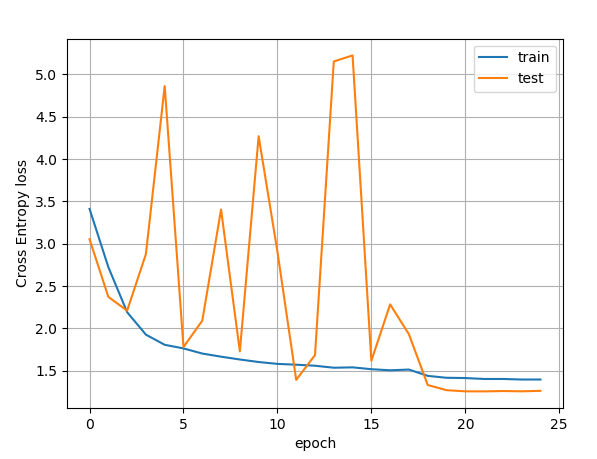
After a fresh installation both condaand torch 1.4.0 and run pz_train_resnet.py
Here is the complete output
### Training model ###
> Parameters:
fake_data: False
use_weighted_class: False
weights_file: ./weights_real.npy
network: resnet20
deterministic: False
benchmark: True
data_augmentation: True
resume: False
checkpoint_file: ./dbg-resnet20_cudnn_False_True_data_True_19.pth
history_loss_cpt_file: ./dbg-history-resnet20_cudnn_False_True_data_True_19.npy
Nepochs: 25
batch_size: 128
test_batch_size: 128
lr_init: 0.01
weight_decay: 0.0
momentum: 0.9
lr_decay: 0.1
no_cuda: False
root_file: ./
train_file: ./data/train_synth_128k.npz
test_file: ./data/test_synth_128k.npz
test_ref_file: ./data/test_synth_10k.npz
Use device....: cuda
DatasetPz zmin: 0.0 zmax: 0.26920348
train_loader length= 1000
DatasetPz zmin: 0.0 zmax: 0.28748795
test_loader length= 1000
DatasetPz zmin: 0.0 zmax: 0.24694234
test_ref_loader length= 1000
=> no checkpoints then Go as fresh start
process epoch[ 0 ]: LR = 0.01
Train Epoch: 0 [0/128000 (0%)] Loss: 5.320686
Train Epoch: 0 [12800/128000 (10%)] Loss: 3.898737
Train Epoch: 0 [25600/128000 (20%)] Loss: 3.346157
Train Epoch: 0 [38400/128000 (30%)] Loss: 3.416076
Train Epoch: 0 [51200/128000 (40%)] Loss: 3.409688
Train Epoch: 0 [64000/128000 (50%)] Loss: 3.272535
Train Epoch: 0 [76800/128000 (60%)] Loss: 3.430590
Train Epoch: 0 [89600/128000 (70%)] Loss: 3.133394
Train Epoch: 0 [102400/128000 (80%)] Loss: 3.237724
Train Epoch: 0 [115200/128000 (90%)] Loss: 3.104288
Epoch 0: Train loss 3.390329, Test loss 3.055378
process epoch[ 1 ]: LR = 0.01
Train Epoch: 1 [0/128000 (0%)] Loss: 3.157166
Train Epoch: 1 [12800/128000 (10%)] Loss: 2.931898
Train Epoch: 1 [25600/128000 (20%)] Loss: 2.797516
Train Epoch: 1 [38400/128000 (30%)] Loss: 2.692738
Train Epoch: 1 [51200/128000 (40%)] Loss: 2.760628
Train Epoch: 1 [64000/128000 (50%)] Loss: 2.577829
Train Epoch: 1 [76800/128000 (60%)] Loss: 2.558679
Train Epoch: 1 [89600/128000 (70%)] Loss: 2.704069
Train Epoch: 1 [102400/128000 (80%)] Loss: 2.542824
Train Epoch: 1 [115200/128000 (90%)] Loss: 2.316350
Epoch 1: Train loss 2.689520, Test loss 2.613821
process epoch[ 2 ]: LR = 0.01
Train Epoch: 2 [0/128000 (0%)] Loss: 2.235262
Train Epoch: 2 [12800/128000 (10%)] Loss: 2.448375
Train Epoch: 2 [25600/128000 (20%)] Loss: 2.172808
Train Epoch: 2 [38400/128000 (30%)] Loss: 2.008214
Train Epoch: 2 [51200/128000 (40%)] Loss: 2.150874
Train Epoch: 2 [64000/128000 (50%)] Loss: 2.022653
Train Epoch: 2 [76800/128000 (60%)] Loss: 2.250418
Train Epoch: 2 [89600/128000 (70%)] Loss: 2.237154
Train Epoch: 2 [102400/128000 (80%)] Loss: 2.100273
Train Epoch: 2 [115200/128000 (90%)] Loss: 1.921085
Epoch 2: Train loss 2.134270, Test loss 3.383083
process epoch[ 3 ]: LR = 0.01
Train Epoch: 3 [0/128000 (0%)] Loss: 1.898702
Train Epoch: 3 [12800/128000 (10%)] Loss: 1.910071
Train Epoch: 3 [25600/128000 (20%)] Loss: 1.906038
Train Epoch: 3 [38400/128000 (30%)] Loss: 1.919383
Train Epoch: 3 [51200/128000 (40%)] Loss: 1.950319
Train Epoch: 3 [64000/128000 (50%)] Loss: 2.249590
Train Epoch: 3 [76800/128000 (60%)] Loss: 1.807280
Train Epoch: 3 [89600/128000 (70%)] Loss: 1.743001
Train Epoch: 3 [102400/128000 (80%)] Loss: 1.672539
Train Epoch: 3 [115200/128000 (90%)] Loss: 1.700225
Epoch 3: Train loss 1.906438, Test loss 2.405946
process epoch[ 4 ]: LR = 0.01
Train Epoch: 4 [0/128000 (0%)] Loss: 1.792982
Train Epoch: 4 [12800/128000 (10%)] Loss: 1.995768
Train Epoch: 4 [25600/128000 (20%)] Loss: 1.786114
Train Epoch: 4 [38400/128000 (30%)] Loss: 2.310982
Train Epoch: 4 [51200/128000 (40%)] Loss: 1.679594
Train Epoch: 4 [64000/128000 (50%)] Loss: 1.858140
Train Epoch: 4 [76800/128000 (60%)] Loss: 1.734475
Train Epoch: 4 [89600/128000 (70%)] Loss: 2.029051
Train Epoch: 4 [102400/128000 (80%)] Loss: 1.617365
Train Epoch: 4 [115200/128000 (90%)] Loss: 1.684498
Epoch 4: Train loss 1.791018, Test loss 1.748214
process epoch[ 5 ]: LR = 0.01
Train Epoch: 5 [0/128000 (0%)] Loss: 1.611643
Train Epoch: 5 [12800/128000 (10%)] Loss: 1.710828
Train Epoch: 5 [25600/128000 (20%)] Loss: 2.593412
Train Epoch: 5 [38400/128000 (30%)] Loss: 1.707401
Train Epoch: 5 [51200/128000 (40%)] Loss: 1.961453
Train Epoch: 5 [64000/128000 (50%)] Loss: 1.802976
Train Epoch: 5 [76800/128000 (60%)] Loss: 2.113782
Train Epoch: 5 [89600/128000 (70%)] Loss: 1.582003
Train Epoch: 5 [102400/128000 (80%)] Loss: 1.725921
Train Epoch: 5 [115200/128000 (90%)] Loss: 1.611629
Epoch 5: Train loss 1.755241, Test loss 2.086664
process epoch[ 6 ]: LR = 0.01
Train Epoch: 6 [0/128000 (0%)] Loss: 1.616312
Train Epoch: 6 [12800/128000 (10%)] Loss: 1.503418
Train Epoch: 6 [25600/128000 (20%)] Loss: 2.340903
Train Epoch: 6 [38400/128000 (30%)] Loss: 1.636487
Train Epoch: 6 [51200/128000 (40%)] Loss: 1.576306
Train Epoch: 6 [64000/128000 (50%)] Loss: 1.867527
Train Epoch: 6 [76800/128000 (60%)] Loss: 1.630743
Train Epoch: 6 [89600/128000 (70%)] Loss: 1.813229
Train Epoch: 6 [102400/128000 (80%)] Loss: 1.605393
Train Epoch: 6 [115200/128000 (90%)] Loss: 1.663178
Epoch 6: Train loss 1.699714, Test loss 2.173417
process epoch[ 7 ]: LR = 0.01
Train Epoch: 7 [0/128000 (0%)] Loss: 1.732373
Train Epoch: 7 [12800/128000 (10%)] Loss: 1.647953
Train Epoch: 7 [25600/128000 (20%)] Loss: 1.845326
Train Epoch: 7 [38400/128000 (30%)] Loss: 1.445140
Train Epoch: 7 [51200/128000 (40%)] Loss: 1.560351
Train Epoch: 7 [64000/128000 (50%)] Loss: 2.023677
Train Epoch: 7 [76800/128000 (60%)] Loss: 1.416010
Train Epoch: 7 [89600/128000 (70%)] Loss: 1.588292
Train Epoch: 7 [102400/128000 (80%)] Loss: 1.494108
Train Epoch: 7 [115200/128000 (90%)] Loss: 1.647289
Epoch 7: Train loss 1.672264, Test loss 2.117444
process epoch[ 8 ]: LR = 0.01
Train Epoch: 8 [0/128000 (0%)] Loss: 1.469485
Train Epoch: 8 [12800/128000 (10%)] Loss: 1.647439
Train Epoch: 8 [25600/128000 (20%)] Loss: 1.428973
Train Epoch: 8 [38400/128000 (30%)] Loss: 1.878252
Train Epoch: 8 [51200/128000 (40%)] Loss: 1.828105
Train Epoch: 8 [64000/128000 (50%)] Loss: 1.483417
Train Epoch: 8 [76800/128000 (60%)] Loss: 1.441302
Train Epoch: 8 [89600/128000 (70%)] Loss: 2.048239
Train Epoch: 8 [102400/128000 (80%)] Loss: 1.543493
Train Epoch: 8 [115200/128000 (90%)] Loss: 1.473774
Epoch 8: Train loss 1.639378, Test loss 1.506937
process epoch[ 9 ]: LR = 0.01
Train Epoch: 9 [0/128000 (0%)] Loss: 2.046196
Train Epoch: 9 [12800/128000 (10%)] Loss: 1.558868
Train Epoch: 9 [25600/128000 (20%)] Loss: 1.516347
Train Epoch: 9 [38400/128000 (30%)] Loss: 1.690874
Train Epoch: 9 [51200/128000 (40%)] Loss: 1.575546
Train Epoch: 9 [64000/128000 (50%)] Loss: 1.593543
Train Epoch: 9 [76800/128000 (60%)] Loss: 1.577022
Train Epoch: 9 [89600/128000 (70%)] Loss: 1.999950
Train Epoch: 9 [102400/128000 (80%)] Loss: 1.789234
Train Epoch: 9 [115200/128000 (90%)] Loss: 1.475634
Epoch 9: Train loss 1.613881, Test loss 3.451141
process epoch[ 10 ]: LR = 0.01
Train Epoch: 10 [0/128000 (0%)] Loss: 1.580945
Train Epoch: 10 [12800/128000 (10%)] Loss: 2.223951
Train Epoch: 10 [25600/128000 (20%)] Loss: 1.444337
Train Epoch: 10 [38400/128000 (30%)] Loss: 1.605886
Train Epoch: 10 [51200/128000 (40%)] Loss: 1.586536
Train Epoch: 10 [64000/128000 (50%)] Loss: 1.499701
Train Epoch: 10 [76800/128000 (60%)] Loss: 1.490300
Train Epoch: 10 [89600/128000 (70%)] Loss: 1.673674
Train Epoch: 10 [102400/128000 (80%)] Loss: 2.197850
Train Epoch: 10 [115200/128000 (90%)] Loss: 1.673982
Epoch 10: Train loss 1.588864, Test loss 1.557337
process epoch[ 11 ]: LR = 0.01
Train Epoch: 11 [0/128000 (0%)] Loss: 1.556844
Train Epoch: 11 [12800/128000 (10%)] Loss: 1.844961
Train Epoch: 11 [25600/128000 (20%)] Loss: 1.458535
Train Epoch: 11 [38400/128000 (30%)] Loss: 1.375953
Train Epoch: 11 [51200/128000 (40%)] Loss: 1.436047
Train Epoch: 11 [64000/128000 (50%)] Loss: 1.849633
Train Epoch: 11 [76800/128000 (60%)] Loss: 1.537056
Train Epoch: 11 [89600/128000 (70%)] Loss: 1.435624
Train Epoch: 11 [102400/128000 (80%)] Loss: 1.599767
Train Epoch: 11 [115200/128000 (90%)] Loss: 1.605106
Epoch 11: Train loss 1.585700, Test loss 1.668659
process epoch[ 12 ]: LR = 0.01
Train Epoch: 12 [0/128000 (0%)] Loss: 1.495607
Train Epoch: 12 [12800/128000 (10%)] Loss: 1.530238
Train Epoch: 12 [25600/128000 (20%)] Loss: 2.538032
Train Epoch: 12 [38400/128000 (30%)] Loss: 1.525211
Train Epoch: 12 [51200/128000 (40%)] Loss: 1.495760
Train Epoch: 12 [64000/128000 (50%)] Loss: 1.428281
Train Epoch: 12 [76800/128000 (60%)] Loss: 1.769440
Train Epoch: 12 [89600/128000 (70%)] Loss: 1.381651
Train Epoch: 12 [102400/128000 (80%)] Loss: 1.482104
Train Epoch: 12 [115200/128000 (90%)] Loss: 2.259009
Epoch 12: Train loss 1.569862, Test loss 1.518431
process epoch[ 13 ]: LR = 0.01
Train Epoch: 13 [0/128000 (0%)] Loss: 2.287203
Train Epoch: 13 [12800/128000 (10%)] Loss: 1.585083
Train Epoch: 13 [25600/128000 (20%)] Loss: 1.639100
Train Epoch: 13 [38400/128000 (30%)] Loss: 1.699521
Train Epoch: 13 [51200/128000 (40%)] Loss: 1.521734
Train Epoch: 13 [64000/128000 (50%)] Loss: 1.514271
Train Epoch: 13 [76800/128000 (60%)] Loss: 1.474493
Train Epoch: 13 [89600/128000 (70%)] Loss: 1.981544
Train Epoch: 13 [102400/128000 (80%)] Loss: 1.451897
Train Epoch: 13 [115200/128000 (90%)] Loss: 1.417693
Epoch 13: Train loss 1.547074, Test loss 2.175302
process epoch[ 14 ]: LR = 0.01
Train Epoch: 14 [0/128000 (0%)] Loss: 1.413782
Train Epoch: 14 [12800/128000 (10%)] Loss: 1.375735
Train Epoch: 14 [25600/128000 (20%)] Loss: 1.556977
Train Epoch: 14 [38400/128000 (30%)] Loss: 1.479784
Train Epoch: 14 [51200/128000 (40%)] Loss: 1.343780
Train Epoch: 14 [64000/128000 (50%)] Loss: 1.462856
Train Epoch: 14 [76800/128000 (60%)] Loss: 1.316921
Train Epoch: 14 [89600/128000 (70%)] Loss: 1.339803
Train Epoch: 14 [102400/128000 (80%)] Loss: 1.429193
Train Epoch: 14 [115200/128000 (90%)] Loss: 1.316347
Epoch 14: Train loss 1.555193, Test loss 2.684988
Epoch 15: reducing learning rate of group 0 to 1.0000e-03.
process epoch[ 15 ]: LR = 0.001
Train Epoch: 15 [0/128000 (0%)] Loss: 1.475628
Train Epoch: 15 [12800/128000 (10%)] Loss: 1.795781
Train Epoch: 15 [25600/128000 (20%)] Loss: 1.372686
Train Epoch: 15 [38400/128000 (30%)] Loss: 1.395689
Train Epoch: 15 [51200/128000 (40%)] Loss: 1.383152
Train Epoch: 15 [64000/128000 (50%)] Loss: 1.662756
Train Epoch: 15 [76800/128000 (60%)] Loss: 1.239338
Train Epoch: 15 [89600/128000 (70%)] Loss: 1.814662
Train Epoch: 15 [102400/128000 (80%)] Loss: 1.631586
Train Epoch: 15 [115200/128000 (90%)] Loss: 1.498583
Epoch 15: Train loss 1.469027, Test loss 1.309816
process epoch[ 16 ]: LR = 0.001
Train Epoch: 16 [0/128000 (0%)] Loss: 1.417184
Train Epoch: 16 [12800/128000 (10%)] Loss: 1.396650
Train Epoch: 16 [25600/128000 (20%)] Loss: 1.477531
Train Epoch: 16 [38400/128000 (30%)] Loss: 1.372185
Train Epoch: 16 [51200/128000 (40%)] Loss: 1.273059
Train Epoch: 16 [64000/128000 (50%)] Loss: 1.311779
Train Epoch: 16 [76800/128000 (60%)] Loss: 1.529363
Train Epoch: 16 [89600/128000 (70%)] Loss: 1.262141
Train Epoch: 16 [102400/128000 (80%)] Loss: 1.417479
Train Epoch: 16 [115200/128000 (90%)] Loss: 1.321335
Epoch 16: Train loss 1.447726, Test loss 1.365872
process epoch[ 17 ]: LR = 0.001
Train Epoch: 17 [0/128000 (0%)] Loss: 1.330619
Train Epoch: 17 [12800/128000 (10%)] Loss: 1.583001
Train Epoch: 17 [25600/128000 (20%)] Loss: 1.504229
Train Epoch: 17 [38400/128000 (30%)] Loss: 1.682137
Train Epoch: 17 [51200/128000 (40%)] Loss: 1.296136
Train Epoch: 17 [64000/128000 (50%)] Loss: 1.346942
Train Epoch: 17 [76800/128000 (60%)] Loss: 1.622898
Train Epoch: 17 [89600/128000 (70%)] Loss: 1.379345
Train Epoch: 17 [102400/128000 (80%)] Loss: 1.636493
Train Epoch: 17 [115200/128000 (90%)] Loss: 1.412685
Epoch 17: Train loss 1.450945, Test loss 1.284079
process epoch[ 18 ]: LR = 0.001
Train Epoch: 18 [0/128000 (0%)] Loss: 1.279265
Train Epoch: 18 [12800/128000 (10%)] Loss: 1.508906
Train Epoch: 18 [25600/128000 (20%)] Loss: 1.440337
Train Epoch: 18 [38400/128000 (30%)] Loss: 1.191915
Train Epoch: 18 [51200/128000 (40%)] Loss: 1.292978
Train Epoch: 18 [64000/128000 (50%)] Loss: 1.376272
Train Epoch: 18 [76800/128000 (60%)] Loss: 1.833224
Train Epoch: 18 [89600/128000 (70%)] Loss: 1.226209
Train Epoch: 18 [102400/128000 (80%)] Loss: 1.862055
Train Epoch: 18 [115200/128000 (90%)] Loss: 1.580888
Epoch 18: Train loss 1.451196, Test loss 1.268514
process epoch[ 19 ]: LR = 0.001
Train Epoch: 19 [0/128000 (0%)] Loss: 1.363650
Train Epoch: 19 [12800/128000 (10%)] Loss: 1.257369
Train Epoch: 19 [25600/128000 (20%)] Loss: 1.475657
Train Epoch: 19 [38400/128000 (30%)] Loss: 1.418347
Train Epoch: 19 [51200/128000 (40%)] Loss: 1.371760
Train Epoch: 19 [64000/128000 (50%)] Loss: 1.385284
Train Epoch: 19 [76800/128000 (60%)] Loss: 1.862140
Train Epoch: 19 [89600/128000 (70%)] Loss: 1.383146
Train Epoch: 19 [102400/128000 (80%)] Loss: 1.536734
Train Epoch: 19 [115200/128000 (90%)] Loss: 1.290726
Epoch 19: Train loss 1.431966, Test loss 1.285855
process epoch[ 20 ]: LR = 0.001
Train Epoch: 20 [0/128000 (0%)] Loss: 1.368411
Train Epoch: 20 [12800/128000 (10%)] Loss: 1.563251
Train Epoch: 20 [25600/128000 (20%)] Loss: 1.437429
Train Epoch: 20 [38400/128000 (30%)] Loss: 1.589489
Train Epoch: 20 [51200/128000 (40%)] Loss: 1.528415
Train Epoch: 20 [64000/128000 (50%)] Loss: 1.317557
Train Epoch: 20 [76800/128000 (60%)] Loss: 1.587386
Train Epoch: 20 [89600/128000 (70%)] Loss: 1.446172
Train Epoch: 20 [102400/128000 (80%)] Loss: 1.564957
Train Epoch: 20 [115200/128000 (90%)] Loss: 1.508901
Epoch 20: Train loss 1.432387, Test loss 1.360785
process epoch[ 21 ]: LR = 0.001
Train Epoch: 21 [0/128000 (0%)] Loss: 1.428193
Train Epoch: 21 [12800/128000 (10%)] Loss: 1.224799
Train Epoch: 21 [25600/128000 (20%)] Loss: 1.508008
Train Epoch: 21 [38400/128000 (30%)] Loss: 2.124377
Train Epoch: 21 [51200/128000 (40%)] Loss: 1.335971
Train Epoch: 21 [64000/128000 (50%)] Loss: 1.565551
Train Epoch: 21 [76800/128000 (60%)] Loss: 1.495022
Train Epoch: 21 [89600/128000 (70%)] Loss: 1.323662
Train Epoch: 21 [102400/128000 (80%)] Loss: 1.365862
Train Epoch: 21 [115200/128000 (90%)] Loss: 1.208025
Epoch 21: Train loss 1.425866, Test loss 1.541909
process epoch[ 22 ]: LR = 0.001
Train Epoch: 22 [0/128000 (0%)] Loss: 2.487714
Train Epoch: 22 [12800/128000 (10%)] Loss: 1.432114
Train Epoch: 22 [25600/128000 (20%)] Loss: 1.435076
Train Epoch: 22 [38400/128000 (30%)] Loss: 1.330877
Train Epoch: 22 [51200/128000 (40%)] Loss: 1.304563
Train Epoch: 22 [64000/128000 (50%)] Loss: 1.463097
Train Epoch: 22 [76800/128000 (60%)] Loss: 1.440692
Train Epoch: 22 [89600/128000 (70%)] Loss: 1.407274
Train Epoch: 22 [102400/128000 (80%)] Loss: 1.356632
Train Epoch: 22 [115200/128000 (90%)] Loss: 1.383518
Epoch 22: Train loss 1.417806, Test loss 1.321678
process epoch[ 23 ]: LR = 0.001
Train Epoch: 23 [0/128000 (0%)] Loss: 1.546077
Train Epoch: 23 [12800/128000 (10%)] Loss: 1.416126
Train Epoch: 23 [25600/128000 (20%)] Loss: 1.540276
Train Epoch: 23 [38400/128000 (30%)] Loss: 1.418480
Train Epoch: 23 [51200/128000 (40%)] Loss: 1.381383
Train Epoch: 23 [64000/128000 (50%)] Loss: 1.282853
Train Epoch: 23 [76800/128000 (60%)] Loss: 1.338777
Train Epoch: 23 [89600/128000 (70%)] Loss: 1.294539
Train Epoch: 23 [102400/128000 (80%)] Loss: 1.301930
Train Epoch: 23 [115200/128000 (90%)] Loss: 1.464347
Epoch 23: Train loss 1.414464, Test loss 1.265200
process epoch[ 24 ]: LR = 0.001
Train Epoch: 24 [0/128000 (0%)] Loss: 1.314852
Train Epoch: 24 [12800/128000 (10%)] Loss: 1.278129
Train Epoch: 24 [25600/128000 (20%)] Loss: 1.617106
Train Epoch: 24 [38400/128000 (30%)] Loss: 1.735250
Train Epoch: 24 [51200/128000 (40%)] Loss: 1.923475
Train Epoch: 24 [64000/128000 (50%)] Loss: 1.495912
Train Epoch: 24 [76800/128000 (60%)] Loss: 1.328095
Train Epoch: 24 [89600/128000 (70%)] Loss: 1.394524
Train Epoch: 24 [102400/128000 (80%)] Loss: 1.345186
Train Epoch: 24 [115200/128000 (90%)] Loss: 1.515934
Epoch 24: Train loss 1.415395, Test loss 1.326887
End of job!
Here my config
Collecting environment information...
PyTorch version: 1.4.0
Is debug build: No
CUDA used to build PyTorch: 10.1
OS: CentOS Linux release 7.7.1908 (Core)
GCC version: (GCC) 4.8.5 20150623 (Red Hat 4.8.5-39)
CMake version: version 2.8.12.2
Python version: 3.7
Is CUDA available: Yes
CUDA runtime version: 10.1.105
GPU models and configuration: GPU 0: Tesla V100-PCIE-32GB
Nvidia driver version: 418.87.01
cuDNN version: /opt/cuda-10.1/targets/x86_64-linux/lib/libcudnn.so.7.5.0
Versions of relevant libraries:
[pip] numpy==1.17.2
[pip] numpydoc==0.9.1
[pip] torch==1.4.0
[pip] torchvision==0.5.0
[conda] blas 1.0 mkl
[conda] mkl 2019.4 243
[conda] mkl-service 2.3.0 py37he904b0f_0
[conda] mkl_fft 1.0.14 py37ha843d7b_0
[conda] mkl_random 1.1.0 py37hd6b4f25_0
[conda] pytorch 1.4.0 py3.7_cuda10.1.243_cudnn7.6.3_0 pytorch
[conda] torchvision 0.5.0 py37_cu101 pytorch
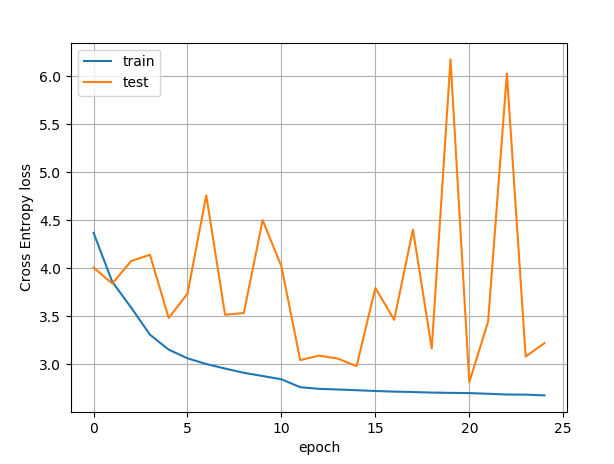
Hello @ptrblck V100 GPU.test loss is still hieratic.
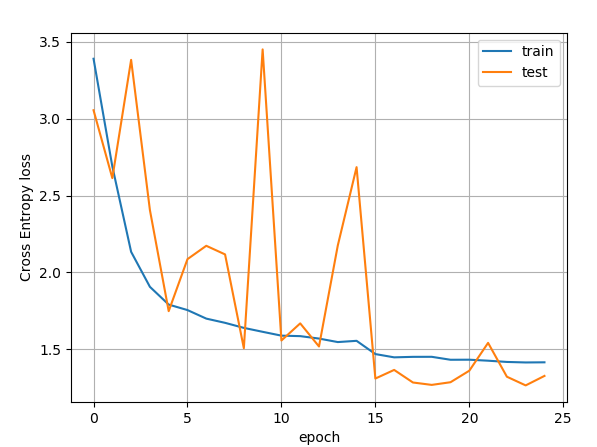
Here the same run but on a K80
I have also tried with K80 on Google Colab (very slow…) I only got 30 epochs with the same stat as just above
It seems that with this few stats the hieratic behaviour appears after epoch 15 or so.