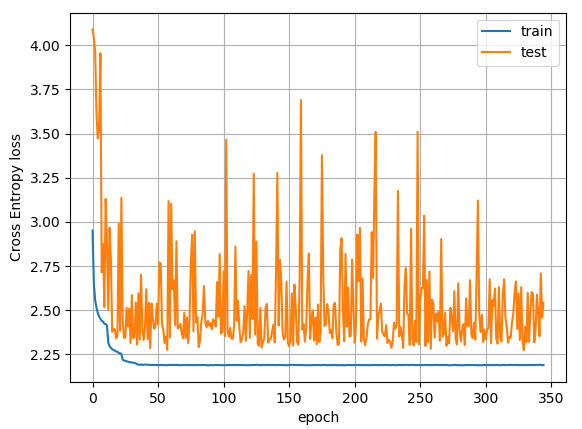
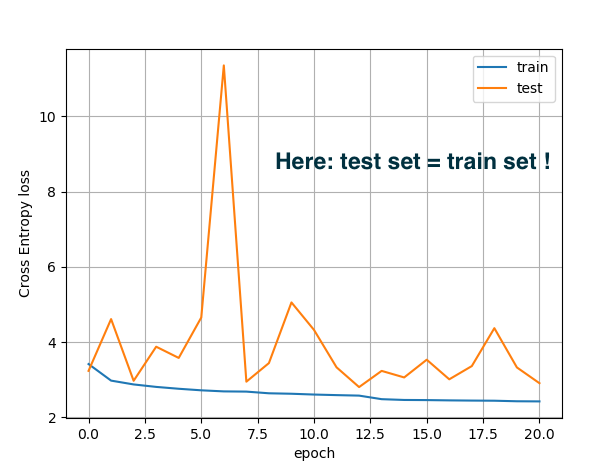
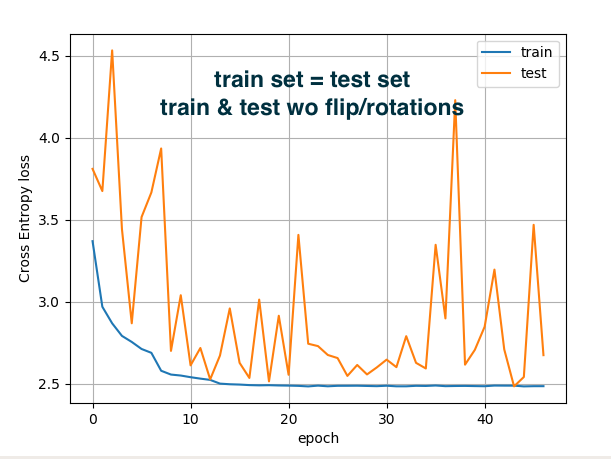
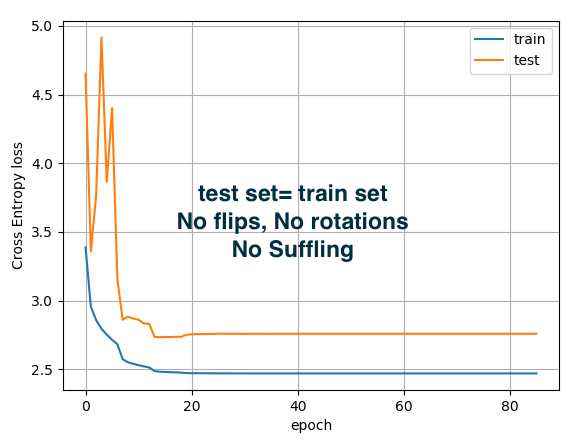
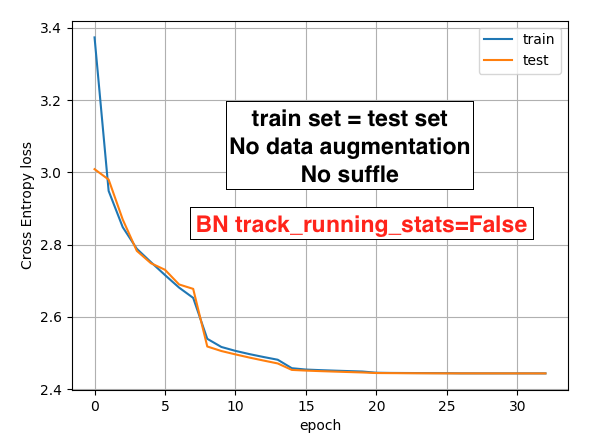
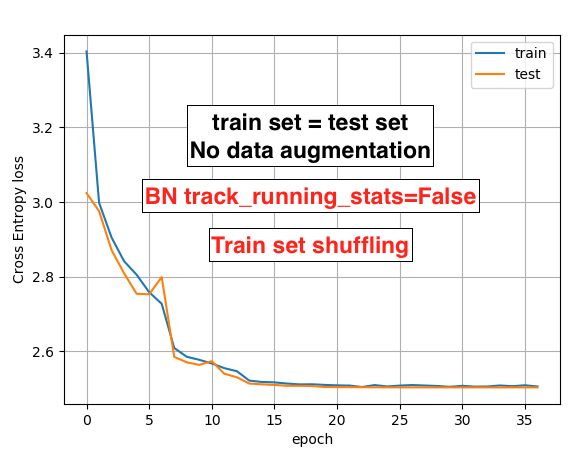
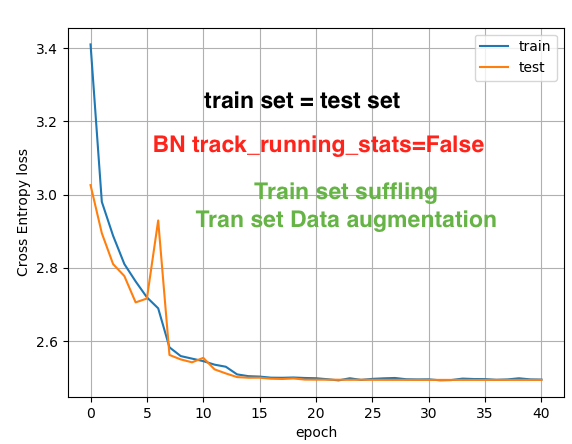
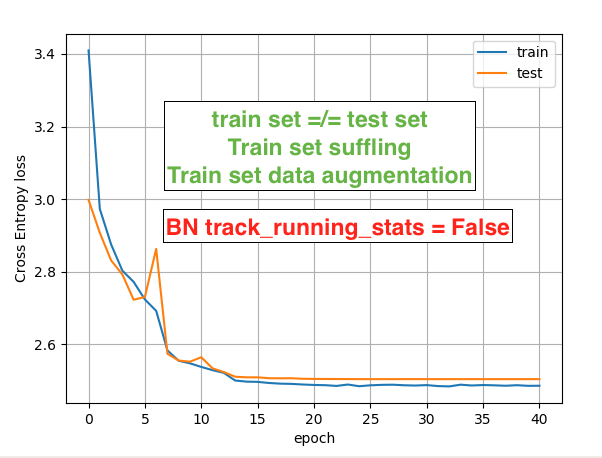
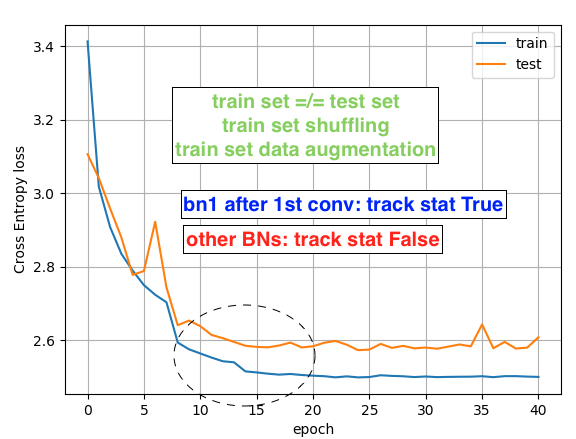
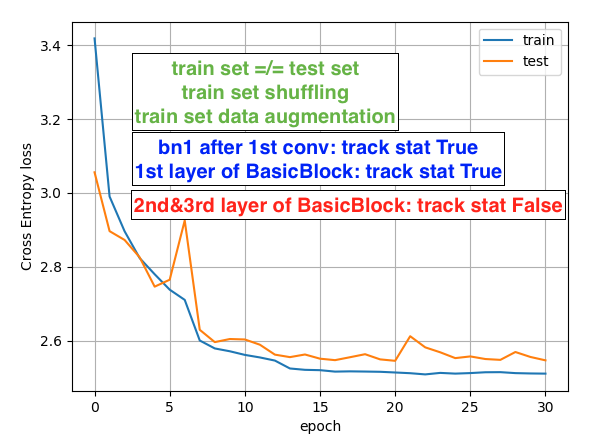
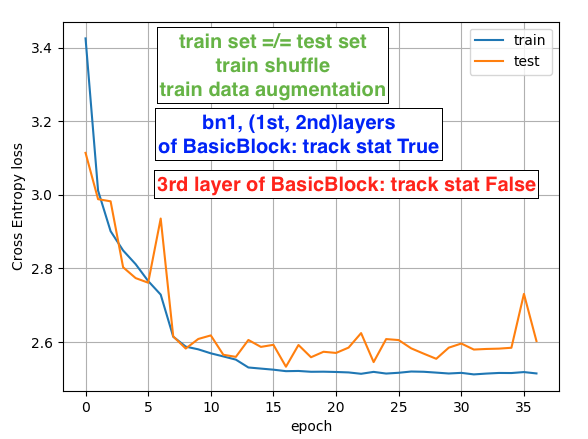
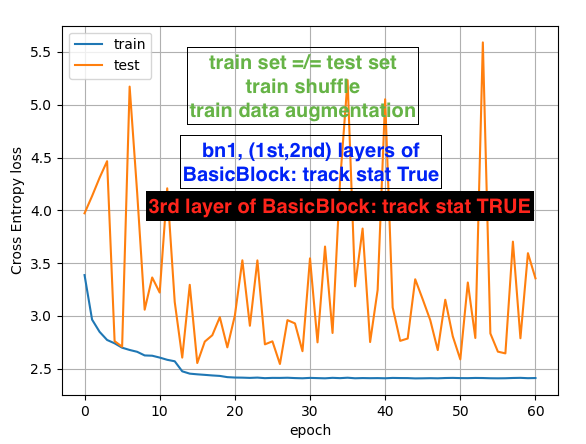
Hi, Best wishes for 2020!
I have set-up a series of script to investigate the (pathologiocal) behaviour of the test loss when training a Resnet model.
As I cannot attach some files it will be a bit tedious, sorry.
(pz_synth_data.py) script to generate synthesized (rubish) data
#This is a script to produce synthetized input data
import numpy as np
from scipy.integrate import quad
from tqdm import tqdm
#####################
class ImgSynthe(object):
""" Synthetisation d'images : C x H x W """
Nfilters = 5
lambda_min0 = 0.05
lambda_max0 = 1.0
noise = 0.01
sig0 = 0.2
strength0 = 1.0
zmean = 0.12
zsig = 0.035
zmin = 0.0
zmax = 0.3
N = 64
x = (np.linspace(0,N-1,N)+0.5)/N
y = (np.linspace(0,N-1,N)+0.5)/N
xv, yv = np.meshgrid(x,y)
def __init__(self):
print("Perform synthetisation")
def shape(self,x,y,norm=1.0,muX=0.,sigX=1.0,muY=0.0,sigY=1.0,rho=0.0):
""" gaussian PSF """
rho2 = 1.0-rho*rho
sigX2 = sigX*sigX
sigY2 = sigY*sigY
return norm *\
np.exp(-0.5/rho2*((x-muX)**2/sigX2+(y-muY)**2/sigY2)-2*rho*(x-muX)*(y-muY)/(sigX*sigY))
def spec(self,x,norm=1.0,xmin=0.,xmax=1.):
""" Simple emission spectrum """
if x < xmin or x > xmax:
return 0.0
else:
return 4.0*norm*(x-xmin)*(xmax-x)/(xmax-xmin)**2
def intspec(self,a,b,norm,xmin,xmax):
""" Integrale du spectre dans [a,b] """
return quad(self.spec,a,b,args=(norm,xmin,xmax))[0]
def __call__(self):
# get z value
z = self.zsig*np.random.randn()+self.zmean
z = np.clip(z,self.zmin,self.zmax)
# update spectral shape
lambda_min = (1+z)*self.lambda_min0
lambda_max = (1+z)*self.lambda_max0
strength = self.strength0/(1+z)**2
#update shape
sig = self.sig0/(1.+z)
sigX = sig*np.random.uniform(0.1,1.0)
sigY = sig*np.random.uniform(0.1,1.0)
rho = np.random.uniform(0.,0.99)
# signal in all filters
filter_imgs = []
for p in range(self.Nfilters):
norm = self.intspec(p/5.,(p+1)/5.,strength,lambda_min,lambda_max)
#print('norm: ',norm)
img = self.shape(self.xv,self.yv,norm=norm,muX=0.5,sigX=sigX,muY=0.5,sigY=sigY,rho=rho)
img += np.random.normal(0,self.noise,size=img.shape)
filter_imgs.append(img)
# transform to float32 to gain space
imgs = np.array(filter_imgs).astype("float32") # Nfilters x H x W
# transpose for compatibility
imgs = np.transpose(imgs,(1,2,0)) # H x W x Nfilters
return { 'image': imgs, 'z':np.float32(z), 'ebv':np.float32(0.) } # ebv for compatibility
########################
def makeSet(gen,N,file="tmp.npz"):
imgs = []
zs = []
ebvs = []
for i in tqdm(range(N),ascii=True,desc=file):
data = gen()
imgs.append(data['image'])
zs.append(data['z'])
ebvs.append(data['ebv'])
zarr = np.array(zs)
zarr = np.expand_dims(zarr,axis=-1)
ebvarr = np.array(ebvs)
ebvarr = np.expand_dims(ebvarr,axis=-1)
np.savez(file,data=np.array(imgs),z=zarr,ebv=ebvarr)
################################
if __name__ == '__main__':
gen = ImgSynthe()
Ntrain = 128*10**3
makeSet(gen,Ntrain,file="train_synth_128k.npz")
Ntest = 128*10**3
makeSet(gen,Ntest,file="test_synth_128k.npz")
Ntest_ref = 10*10**3
makeSet(gen,Ntest_ref,file="test_synth_10k.npz")
print("All done. Bye")
pz_utils.py : Now a utility script to be used for the training, it deals with classes for the Data laoding and the Network design (Resnet and a simple ConvNet)
import random
import torch
import torch.nn as nn
from torchvision import transforms
from torch.utils.data import DataLoader, Dataset
import torch.optim as optim
import torch.nn.functional as F
import torch.nn.init as init #for ResNetV2
import numpy as np
########### A simple convnet ########
class PzConv2d(nn.Module):
""" Convolution 2D Layer followed by PReLU activation
"""
def __init__(self, n_in_channels, n_out_channels, **kwargs):
super(PzConv2d, self).__init__()
self.conv = nn.Conv2d(n_in_channels, n_out_channels, bias=True,
**kwargs)
nn.init.xavier_uniform_(self.conv.weight)
nn.init.constant_(self.conv.bias,0.1)
self.activ = nn.PReLU(num_parameters=n_out_channels, init=0.25)
def forward(self, x):
x = self.conv(x)
return self.activ(x)
class PzPool2d(nn.Module):
""" Average Pooling Layer
"""
def __init__(self, kernel_size, stride, padding=0):
super(PzPool2d, self).__init__()
self.pool = nn.AvgPool2d(kernel_size=kernel_size,
stride=stride,
padding=padding,
ceil_mode=True,
count_include_pad=False)
def forward(self, x):
return self.pool(x)
class PzFullyConnected(nn.Module):
""" Dense or Fully Connected Layer followed by ReLU
"""
def __init__(self, n_inputs, n_outputs, withrelu=True, **kwargs):
super(PzFullyConnected, self).__init__()
self.withrelu = withrelu
self.linear = nn.Linear(n_inputs, n_outputs, bias=True)
nn.init.xavier_uniform_(self.linear.weight)
nn.init.constant_(self.linear.bias, 0.1)
self.activ = nn.ReLU()
def forward(self, x):
x = self.linear(x)
if self.withrelu:
x = self.activ(x)
return x
class NetCNNRed(nn.Module):
def __init__(self,n_input_channels,debug=False):
super(NetCNNRed, self).__init__()
self.debug = debug
# the number of bins to represent the output photo-z
self.n_bins = 180
self.conv0 = PzConv2d(n_in_channels=n_input_channels,
n_out_channels=64,
kernel_size=5,padding=2)
self.pool0 = PzPool2d(kernel_size=2,stride=2,padding=0)
self.conv1 = PzConv2d(n_in_channels=64,
n_out_channels=92,
kernel_size=3,padding=2)
self.pool1 = PzPool2d(kernel_size=2,stride=2,padding=0)
self.conv2 = PzConv2d(n_in_channels=92,
n_out_channels=128,
kernel_size=3,padding=2)
self.pool2 = PzPool2d(kernel_size=2,stride=2,padding=0)
self.fc0 = PzFullyConnected(n_inputs=12801,n_outputs=1024)
self.fc1 = PzFullyConnected(n_inputs=1024,n_outputs=180)
def num_flat_features(self, x):
size = x.size()[1:] # all dimensions except the batch dimension
num_features = 1
for s in size:
num_features *= s
return num_features
def forward(self, x, reddening):
# x:image tenseur N_batch, Channels, Height, Width
# size N, Channles=5 filtres, H,W = 64 pixels
# reddening: used
#save original image
## x_in = x
if self.debug: print("input shape: ",x.size())
# stage 0 conv 64 x 5x5
x = self.conv0(x)
if self.debug: print("conv0 shape: ",x.size())
x = self.pool0(x)
if self.debug: print("conv0p shape: ",x.size())
# stage 1 conv 92 x 3x3
x = self.conv1(x)
if self.debug: print("conv1 shape: ",x.size())
x = self.pool1(x)
if self.debug: print("conv1p shape: ",x.size())
# stage 2 conv 128 x 3x3
x = self.conv2(x)
if self.debug: print("conv2 shape: ",x.size())
x = self.pool2(x)
if self.debug: print("conv2p shape: ",x.size())
if self.debug: print('>>>>>>> FC part :START <<<<<<<')
flat = x.view(-1,self.num_flat_features(x))
concat = torch.cat((flat,reddening),dim=1)
if self.debug: print('concat shape: ', concat.size())
x = self.fc0(concat)
if self.debug: print('fc0 shape: ',x.size())
x = self.fc1(x)
if self.debug: print('fc1 shape: ', x.size())
output = x
if self.debug: print('output shape: ',output.size())
## params = {"output": output, "x": x_in, "reddening": reddening}
#return params
return output
################### Resnet ##########
## Code adapeted from https://github.com/akamaster/pytorch_resnet_cifar10/blob/master/resnet.py
def _weights_init(m):
classname = m.__class__.__name__
#print(classname)
if isinstance(m, nn.Linear) or isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight)
class LambdaLayer(nn.Module):
def __init__(self, lambd):
super(LambdaLayer, self).__init__()
self.lambd = lambd
def forward(self, x):
return self.lambd(x)
class BasicBlockV2(nn.Module):
expansion = 1
def __init__(self, in_planes, planes, stride=1, option='A', h=1.0, track_run_stat=True, debug=False):
super(BasicBlockV2, self).__init__()
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes,track_running_stats=track_run_stat) # true is the default
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes,track_running_stats=track_run_stat)
self.h = h
self.debug = debug
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != planes:
if option == 'A':
"""
For CIFAR10 ResNet paper uses option A.
"""
self.shortcut = LambdaLayer(lambda x:
F.pad(x[:, :, ::2, ::2], (0, 0, 0, 0, planes//4, planes//4), "constant", 0))
elif option == 'B':
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion * planes, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion * planes, track_running_stats=False)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
if self.debug:
print('last bn2: ',self.bn2.weight,', ',
self.bn2.bias,', ',
self.bn2.running_mean,', ',
self.bn2.running_var)
out = self.shortcut(x) + self.h * out # Zhang et al. h=1 for the default Resnet
out = F.relu(out)
return out
class ResNetV2(nn.Module):
def __init__(self, block, num_blocks, num_input_channels = 5, num_classes=10, h=1.0):
super(ResNetV2, self).__init__()
self.in_planes = 16
self.num_input_channels = num_input_channels
self.n_bins = num_classes
## self.conv1 = nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1, bias=False)
self.conv1 = nn.Conv2d(self.num_input_channels, 16, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(16,track_running_stats=True) # track_running_stats=True is the default
self.layer1 = self._make_layer(block, 16, num_blocks[0], stride=1, h=h, track_run_stat=True)
self.layer2 = self._make_layer(block, 32, num_blocks[1], stride=2, h=h, track_run_stat=True)
self.layer3 = self._make_layer(block, 64, num_blocks[2], stride=2, h=h, track_run_stat=True)
## self.linear = nn.Linear(64, num_classes)
## JEC add redenning variable
self.linear = nn.Linear(64+1, num_classes)
self.apply(_weights_init)
def _make_layer(self, block, planes, num_blocks, stride, h=1.0, track_run_stat=True, debug=False):
strides = [stride] + [1]*(num_blocks-1)
layers = []
for stride in strides:
layers.append(block(self.in_planes, planes, stride, h=h, track_run_stat=track_run_stat, debug=debug))
self.in_planes = planes * block.expansion
return nn.Sequential(*layers)
def forward(self, x, reddening):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = F.avg_pool2d(out, out.size()[3])
out = out.view(out.size(0), -1)
out = torch.cat((out,reddening),dim=1) ## add the redenning
out = self.linear(out)
return out
def resnet20(h=0.1):
return ResNetV2(BasicBlockV2, [3, 3, 3], num_input_channels = 5, num_classes=180, h=h)
## ################ Data load/augmentation #########
class DatasetPz(Dataset):
""" Load the data set which is supposed to be a Numpy structured array
'z' : the true redshift array
'ebv': reddening array
'data': the images tensors N H W C with C: nber of channels (ex. 5 filters)
"""
def __init__(self, file_path, transform=None):
self.data = np.load(file_path) # load dataset into numpy array N H W C
#print('type de dataset data = ',self.data['data'].dtype)
#transform into Float32
self.z = self.data['z'].astype("float32")
self.ebv = self.data['ebv'].astype("float32")
self.imgs = self.data['data'].astype("float32")
self.z_min = np.min(self.z)
self.z_max = np.max(self.z)
print("DatasetPz zmin: ",self.z_min," zmax: ",self.z_max)
self.transform = transform
def __len__(self):
return len(self.imgs)
def __getitem__(self, index):
"""
Parameters
----------
index: index of the image, redshift, reddening
Returns
-------
a dictionary with the image, redshift, reddening
Apply a transform to the image if needed
"""
image = self.imgs[index]
if self.transform is not None:
image = self.transform(image)
return {'image': image, 'z': self.z[index], 'ebv': self.ebv[index]}
class ToTensorPz(object):
""" Transform the tensor from HWC(TensorFlow default) to CHW (Torch)
"""
def __call__(self, pic):
# use copy here to avoid crash
img = torch.from_numpy(pic.transpose((2, 0, 1)).copy())
return img
def __repr__(self):
return self.__class__.__name__ + '()'
class RandomApplyPz(transforms.RandomApply):
"""Apply randomly a list of transformations with a given probability
Args:
transforms (list or tuple): list of transformations
p (float): list of probabilities
"""
def __init__(self, transforms):
super(RandomApplyPz, self).__init__(transforms)
def __call__(self, img):
# for each list of transforms
# apply random sample to apply or not the transform
for itset in range(len(self.transforms)):
transf = self.transforms[itset]
t = random.choice(transf)
#### print('t:=',t)
img = t(img)
return img
def flipH(a):
"""
Parameters
----------
a: an image
Returns
-------
an image flipped wrt the Horizontal axe
"""
return np.flip(a,0)
def flipV(a):
"""
Parameters
----------
a: an image
Returns
-------
an image flipped wrt the Vertical axe
"""
return np.flip(a,1)
def rot90(a):
"""
Parameters
----------
a: an image
Returns
-------
an image rotated 90deg anti-clockwise
"""
return np.rot90(a,1)
def rot180(a):
"""
Parameters
----------
a: an image
Returns
-------
an image rotated 180deg anti-clockwise
"""
return np.rot90(a,2)
def rot270(a):
"""
Parameters
----------
a: an image
Returns
-------
an image rotated 270deg anti-clockwise
"""
return np.rot90(a,3)
def identity(a):
"""
Parameters
----------
a: an image
Returns
-------
the same image
"""
return a