Hi everyone, I’m training a ResNet18 model and I plan to use it for a regression task, but after seeing that my validation set errors were constant, I noticed that the weights in my model are not being updates. Could anyone give me a hand with it?
I produced a MWE with my modified ResNet model (I changed the last linear layer so the output size is 1), with a randomly generated dataset of 40 images and 40 labels, I’m using SGD as my optimizer and my objective function is RMSE. Within my training loop I’m trying to compare if gradients are computed and if the parameters are updated, but despite a gradient being computed the parameters are not updated at all.
I have tried adding model.train(mode=True) to my code, but it didn’t change anything.
import torch
from torch.utils.data.dataloader import DataLoader
import torchvision
from torchvision.transforms import Normalize
model=torchvision.models.resnet18(weights=torchvision.models.ResNet18_Weights.IMAGENET1K_V1)
#modifying base model (we modify the last fully connected layer to have output size=1 for our regression task)
model.fc=torch.nn.Linear(512, 1)
model.to('cuda')
#shallow copy of original parameters
orig_params =model.state_dict().copy()
#defining class for our dataset
class RegData(torch.utils.data.Dataset):
def __init__(self, images,labels):
self.images=images
self.labels=labels
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
return self.images[idx], self.labels[idx]
#building dataset (images between 0 and 1, and labels (random normal))
images=Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225])(torch.rand(40,3,224,224))
train_set=RegData(images,torch.normal(10, 30, size=(40,1)))
#training set dataloader
train_data= DataLoader( train_set ,batch_size=10, shuffle=False,
generator=torch.Generator().manual_seed(0))
#optimizer
optimizer=torch.optim.SGD(model.parameters(), lr=0.1, momentum=0)
#loss function
loss_fun = torch.nn.MSELoss()
#training loop
batch=0
for X,y in train_data:
#sending data to device
X_batch=X.to('cuda')
y_batch=y.to('cuda')
# zero the parameter gradients
optimizer.zero_grad()
#forward pass with gradient enabled
with torch.set_grad_enabled(True):
output = model(X_batch)
loss = torch.sqrt(loss_fun(output, y_batch))
#print(loss.item())
#backward pass
loss.backward() #computes the gradient
optimizer.step() #computes the parameter update based on the gradient
#mean of the gradient for conv1
grad_mean=torch.mean(model.conv1.weight).item()
#max of the gradient for conv1
grad_max=torch.max(model.conv1.weight).item()
print(f'Mean of gradient of conv1 layer for batch {batch}: {grad_mean}')
print(f'Max of gradient of conv1 layer for batch {batch}: {round(grad_max,5)}')
#comparing weights
print("Are conv1 weights the same after update?")
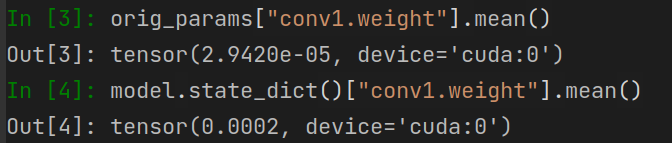
print(torch.equal(orig_params["conv1.weight"],model.state_dict()["conv1.weight"]))
batch+=1
When I run this, I get the following output:
Mean of gradient of conv1 layer for batch 0: 2.6899280783254653e-05
Max of gradient of conv1 layer for batch 0: 1.01465
Are conv1 weights the same after update?
True
Mean of gradient of conv1 layer for batch 1: 0.0006417091353796422
Max of gradient of conv1 layer for batch 1: 1.01661
Are conv1 weights the same after update?
True
Mean of gradient of conv1 layer for batch 2: 0.0006053730612620711
Max of gradient of conv1 layer for batch 2: 1.01476
Are conv1 weights the same after update?
True
Mean of gradient of conv1 layer for batch 3: 0.0008015413768589497
Max of gradient of conv1 layer for batch 3: 1.01373
Are conv1 weights the same after update?
True