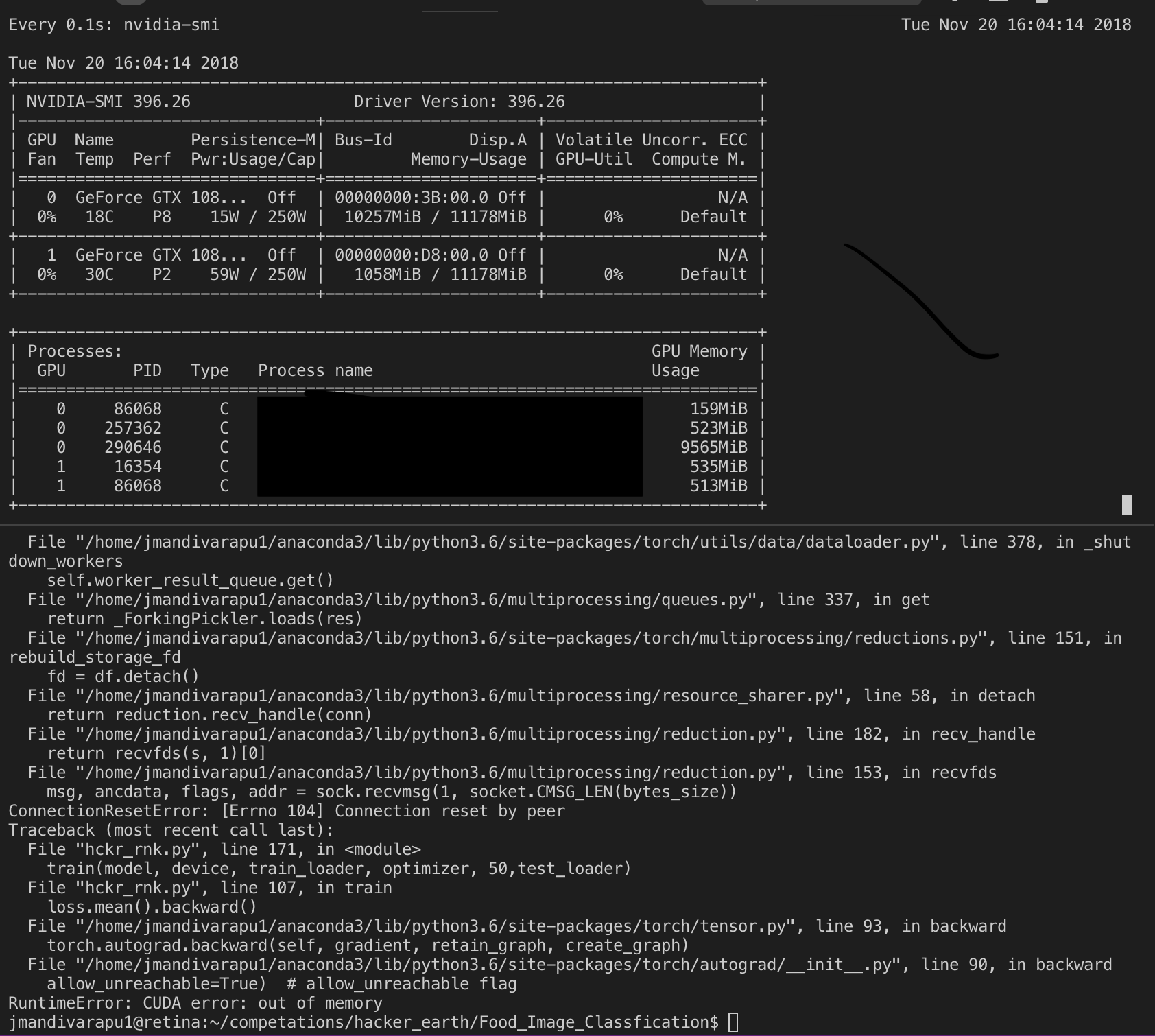
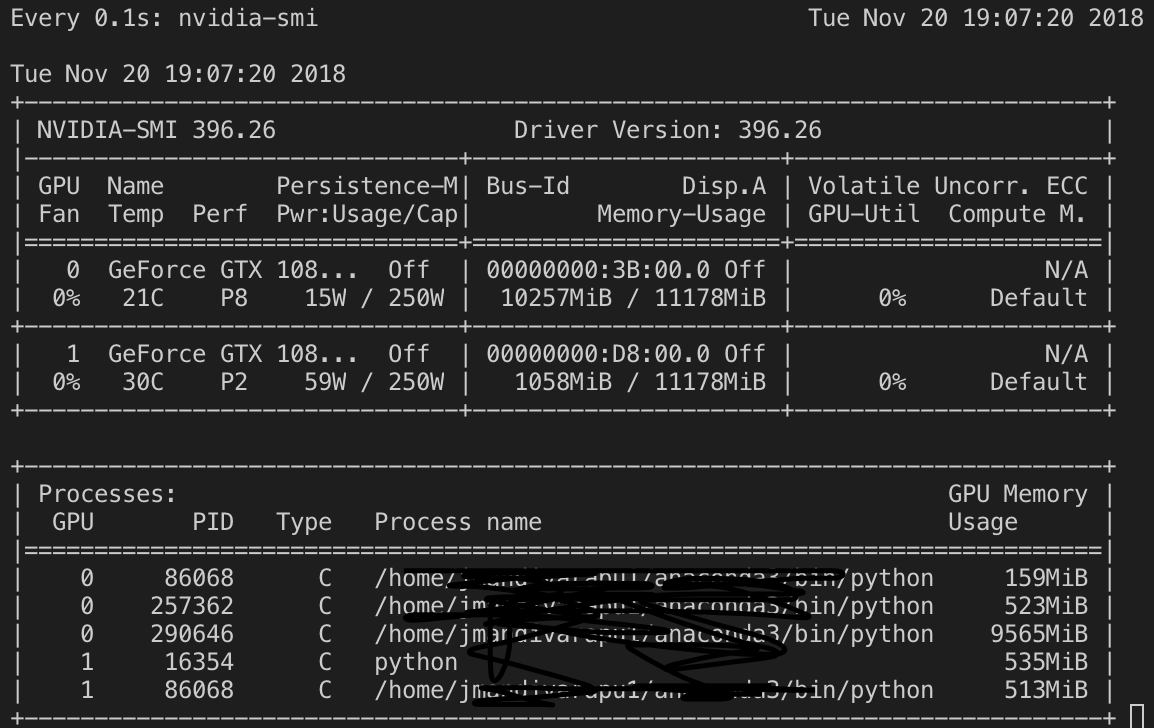
I need some help. I bit new to using higher batches sizes on the GPU. my data set s so big 500K images so I need to use bigger batchsize and larger net. But I was not successful until now to make this work.
train_loader = DataLoader(dset,batch_size=16,shuffle=True,num_workers=4)# pin_memory=True # CUDA only
test_loader = DataLoader(dset_test,batch_size=32,shuffle=False,num_workers=4)# pin_memory=True # CUDA only
use_cuda = torch.cuda.is_available()
model =torchvision.models.resnet18(pretrained='imagenet')
num_ftrs = model.fc.in_features
model.fc = nn.Linear(num_ftrs, 43)
if use_cuda:
model.cuda()
model = torch.nn.DataParallel(model, device_ids=range(torch.cuda.device_count()))
cudnn.benchmark = True
But nothing seems to work. Everytime it’s throwing me a CUDA Memory error.
I want to know is my GPU is not big enough or what is my issue? I need a higher batch size.
Traceback (most recent call last):
File "hckr_rnk.py", line 171, in <module>
train(model, device, train_loader, optimizer, 50,test_loader)
File "hckr_rnk.py", line 105, in train
output = model(data)
File "/home/jmandivarapu1/anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 477, in __call__
result = self.forward(*input, **kwargs)
File "/home/jmandivarapu1/anaconda3/lib/python3.6/site-packages/torch/nn/parallel/data_parallel.py", line 123, in forward
outputs = self.parallel_apply(replicas, inputs, kwargs)
File "/home/jmandivarapu1/anaconda3/lib/python3.6/site-packages/torch/nn/parallel/data_parallel.py", line 133, in parallel_apply
return parallel_apply(replicas, inputs, kwargs, self.device_ids[:len(replicas)])
File "/home/jmandivarapu1/anaconda3/lib/python3.6/site-packages/torch/nn/parallel/parallel_apply.py", line 77, in parallel_apply
raise output
File "/home/jmandivarapu1/anaconda3/lib/python3.6/site-packages/torch/nn/parallel/parallel_apply.py", line 53, in _worker
output = module(*input, **kwargs)
File "/home/jmandivarapu1/anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 477, in __call__
result = self.forward(*input, **kwargs)
File "/home/jmandivarapu1/anaconda3/lib/python3.6/site-packages/torchvision-0.2.1-py3.6.egg/torchvision/models/resnet.py", line 144, in forward
File "/home/jmandivarapu1/anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 477, in __call__
result = self.forward(*input, **kwargs)
File "/home/jmandivarapu1/anaconda3/lib/python3.6/site-packages/torch/nn/modules/container.py", line 91, in forward
input = module(input)
File "/home/jmandivarapu1/anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 477, in __call__
result = self.forward(*input, **kwargs)
File "/home/jmandivarapu1/anaconda3/lib/python3.6/site-packages/torchvision-0.2.1-py3.6.egg/torchvision/models/resnet.py", line 77, in forward
File "/home/jmandivarapu1/anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 477, in __call__
result = self.forward(*input, **kwargs)
File "/home/jmandivarapu1/anaconda3/lib/python3.6/site-packages/torch/nn/modules/batchnorm.py", line 66, in forward
exponential_average_factor, self.eps)
File "/home/jmandivarapu1/anaconda3/lib/python3.6/site-packages/torch/nn/functional.py", line 1254, in batch_norm
training, momentum, eps, torch.backends.cudnn.enabled
RuntimeError: CUDA error: out of memory