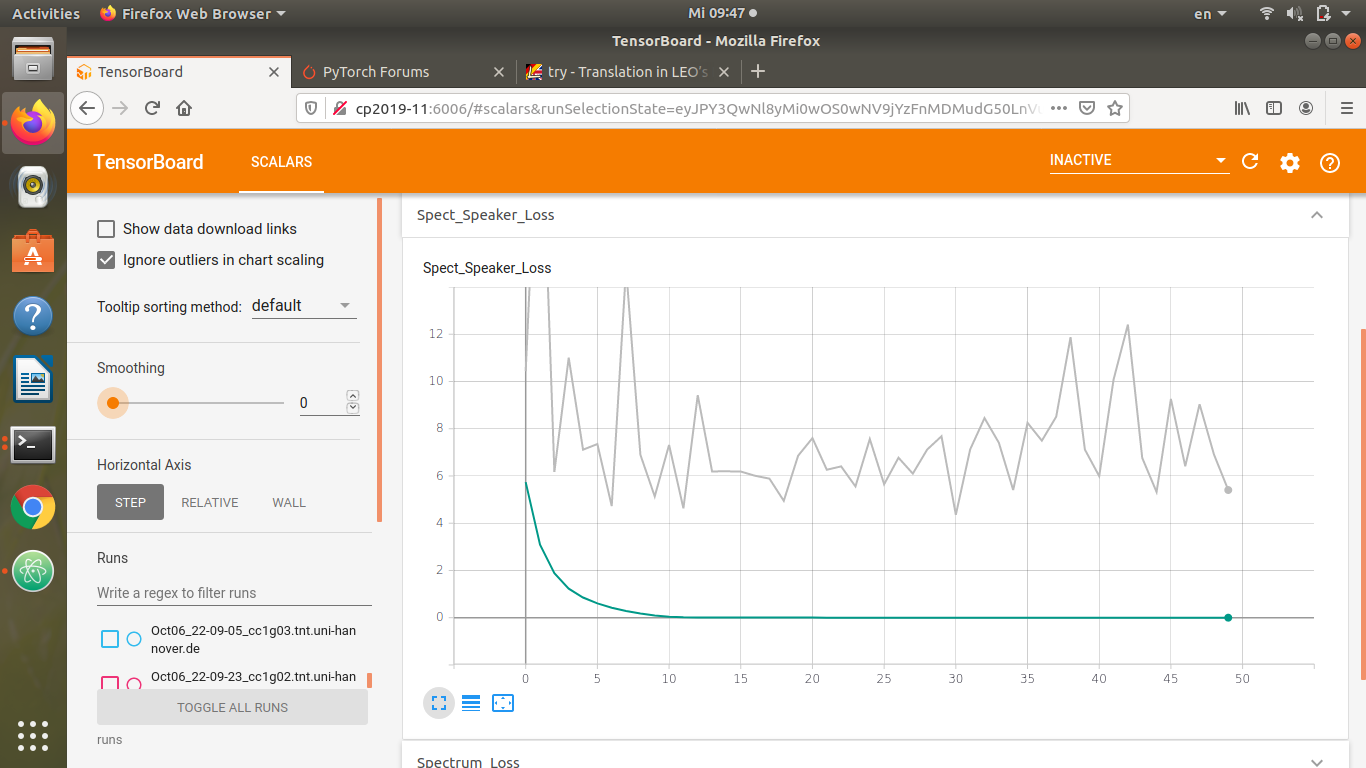
Hi everyone, I’m trying to use pretrained resnet18 for my project and it fits very good to my train data but not to validation data. I have tried changing batch size, convolutionlayers, lr_scheduler but there’s still no success.
This is my first project in DNN and I am a beginner. Can someone please give me a suggestion what can I do? Green is Train Loss and gray Validation Loss.
My Code looks like:
class Resnet_Speaker_Recognition(nn.Module):
def init(self):
super(Resnet_Speaker_Recognition, self).init()
How large are your current training, validation, and test datasets?
Generally more samples help in this scenario. Additionally you could increase the regularization (such as adding or increasing dropout or adding weight decay), adding more data augmentation etc.
It can also be useful to check the training and validation datasets manually and make sure the samples come from the same domain and are thus “similar”.
Hi, thank you for your answer. I am using VoxCeleb 1 as my dataset and it contains 138361 files for training, 8251 for test and 6904 files for validation. There are 1251 speakers to be identified. I was using till now optim.SGD as my optimizer, now I’m trying optim.Adam. It is a bit better but I’m still not having results. Could ypu please give me an simple example how to increase dropout?
I have changed my model again:
class Resnet_Speaker_Recognition(nn.Module):
def init(self):
super(Resnet_Speaker_Recognition, self).init()
I think resnets don’t use dropout initially so you could add e.g. an nn.Sequential module as self.resnet_model.fc containing linear and dropout layers and could check, if it can improve the training.