I’m trying to continue training after saving my models and optimizers. However, it seems some part of the optimizer (Adam) is not being saved, because when I restart training from a checkpoint, the values move rapidly from the old training path, but then stabilize again. For example, the following three plots show this, with each line being a single trial, where the second line is the loaded version of the trial. Note, this is a GAN, so these values are not all expected to nicely descend, and you can ignore what each of these values refer to. Just that they’re not continuing when loaded as they were when not loaded.
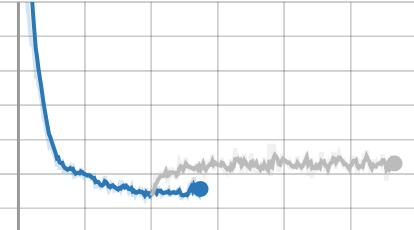
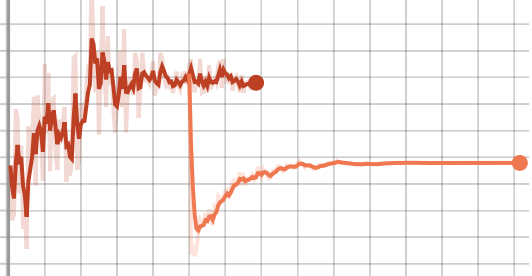
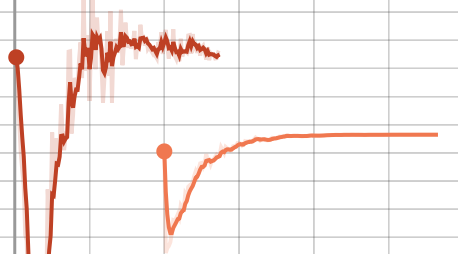
I would expect the loaded versions to roughly follow what the non-loaded versions had done, but they clearly deviate very quickly at the beginning. I’m guessing I’m just doing something incorrectly during my model/optimizer loading/saving, but I’m not sure what it is. Below is (approximately) what I’m using to load and save the training states.
generator_optimizer = Adam(generator.parameters())
discriminator_optimizer = Adam(discriminator.parameters())
# Load from files.
d_model_state_dict = torch.load(d_model_path)
d_optimizer_state_dict = torch.load(d_optimizer_path)
g_model_state_dict = torch.load(g_model_path)
g_optimizer_state_dict = torch.load(g_optimizer_path)
with open(meta_path, 'rb') as pickle_file:
metadata = pickle.load(pickle_file)
step = metadata['step']
epoch = metadata['epoch']
# Restore discriminator.
discriminator.load_state_dict(d_model_state_dict)
discriminator_optimizer.load_state_dict(d_optimizer_state_dict)
discriminator_optimizer.param_groups[0].update({'lr': initial_learning_rate,
'weight_decay': weight_decay})
discriminator_scheduler = lr_scheduler.LambdaLR(discriminator_optimizer,
lr_lambda=learning_rate_multiplier_function)
discriminator_scheduler.step(epoch)
# Restore generator.
generator.load_state_dict(g_model_state_dict)
generator_optimizer.load_state_dict(g_optimizer_state_dict)
generator_optimizer.param_groups[0].update({'lr': initial_learning_rate})
generator_scheduler = lr_scheduler.LambdaLR(generator_optimizer, lr_lambda=learning_rate_multiplier_function)
generator_scheduler.step(epoch)
...
# Save.
torch.save(discriminator.state_dict(), d_model_path)
torch.save(discriminator_optimizer.state_dict(), d_optimizer_path)
torch.save(generator.state_dict(), g_model_path)
torch.save(generator_optimizer.state_dict(), g_optimizer_path)
with open(meta_path, 'wb') as pickle_file:
pickle.dump({'epoch': epoch, 'step': step}, pickle_file)
Does anyone know if there’s anything here I’m obviously doing wrong that I’m missing? I should also note, I have setup the code so that I can start a new trial of training (reseting the learning rate and whatnot) so that I don’t have to train from scratch. Perhaps there’s something I did wrong there causing the continuation training to have problems? Or did I make some other mistake in loading? Or is this due to some limitation with PyTorch’s current loading apparatus? Thank you for your time!