I’m learning DDP and want to realize a function which can resume training from the last snapshot to produce exactly same result as the model trained from scratch. I have read the REPRODUCIBILITY article and do the settings as possible as I can to guarantee a deterministic behavior.
My environment is:
Ubuntu 20.04
Python 3.10
Pytorch 1.12
CUDA Version 11.6
Here is my code named mnist_demo_multi_resume.py:
import torch
import torchvision
from torchvision import transforms
import torch.nn.functional as F
from torch.utils.data import DataLoader, Subset
from torch.utils.data.distributed import DistributedSampler
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.distributed import init_process_group, destroy_process_group
import os
import random
import numpy as np
from natsort import natsorted
def ddp_setup():
init_process_group(backend='nccl')
def init_seeds(seed):
# refer to https://pytorch.org/docs/stable/notes/randomness.html
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
os.environ["CUBLAS_WORKSPACE_CONFIG"] =":16:8"
torch.use_deterministic_algorithms(mode=True, warn_only=True)
class Trainer:
def __init__(self, model, loader, optimizer, save_every, snapshots_dir="./snapshots"):
self.loader = loader
self.optimizer = optimizer
self.save_every = save_every
self.local_rank = int(os.environ["LOCAL_RANK"])
self.epoch = 0
self.model = model.to(self.local_rank)
if not os.path.exists(snapshots_dir):
os.mkdir(snapshots_dir)
last_spst = natsorted(os.listdir(snapshots_dir))[-1] if os.listdir(snapshots_dir) != [] else ' '
snapshot_path = os.path.join(snapshots_dir, last_spst)
if os.path.exists(snapshot_path):
self._load_snapshot(snapshot_path)
self.model = DDP(self.model, device_ids=[self.local_rank])
def _load_snapshot(self, snapshot_path):
snapshot = torch.load(snapshot_path)
self.model.load_state_dict(snapshot["MODEL_STATE"])
self.optimizer.load_state_dict(snapshot["OPTIMIZER_STATE"])
self.epoch = snapshot["EPOCH"]
print(f"Resuming training from snapshot {snapshot_path} at Epoch {self.epoch}")
def _save_snapshot(self):
snapshot = {
"MODEL_STATE": self.model.module.state_dict(),
"OPTIMIZER_STATE": self.optimizer.state_dict(),
"EPOCH": self.epoch,
}
PATH = "snapshots/snapshot_{}.pt".format(self.epoch)
torch.save(snapshot, PATH)
print(f"Epoch {self.epoch} | Training snapshot saved at {PATH}")
def _run_batch(self, batch_idx, source, targets):
self.optimizer.zero_grad()
output = self.model(source)
loss = F.cross_entropy(output, targets)
loss.backward()
self.optimizer.step()
self.loss = loss.item()
def _run_epoch(self):
for batch_idx, data in enumerate(self.loader, 1):
source, targets = data
source, targets = source.cuda(self.local_rank), targets.cuda(self.local_rank)
self._run_batch(batch_idx, source, targets)
if batch_idx == len(self.loader):
print(f"[GPU{self.local_rank}] "
f"[Epoch {self.epoch}, {batch_idx}/{len(self.loader)} "
f"Batchsize: {self.loader.batch_size}] "
f"Loss: {self.loss:.4f} "
f"TgExample: {data[1][:20]}")
def train(self, max_epochs):
for epoch in range(self.epoch+1, max_epochs+1):
self.epoch = epoch
self.loader.sampler.set_epoch(epoch)
self._run_epoch()
if self.local_rank == 0 and self.epoch % self.save_every == 0:
self._save_snapshot()
def prepare_dataloader(data_size=-1, batch_size=256):
trans = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (1.0,))])
dataset = torchvision.datasets.MNIST("./Datasets",
train=True,
transform=trans,
target_transform=None,
download=True)
if data_size != -1:
dataset = Subset(dataset, range(data_size)) # first-n data
loader = DataLoader(dataset=dataset,
batch_size=batch_size,
sampler=DistributedSampler(dataset))
return loader
def load_train_objs():
model = torchvision.models.resnet50(num_classes=10)
model.conv1 = torch.nn.Conv2d(1, 64, (7, 7), (2, 2), (3, 3), bias=False)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
return model, optimizer
def main(max_epochs, save_every):
init_seeds(233)
ddp_setup()
model, optimizer = load_train_objs()
loader = prepare_dataloader(data_size=-1, batch_size=256)
trainer = Trainer(model, loader, optimizer, save_every)
trainer.train(max_epochs)
destroy_process_group()
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('max_epochs', type=int)
parser.add_argument('save_every', type=int)
args = parser.parse_args()
main(args.max_epochs, args.save_every)
Experiment
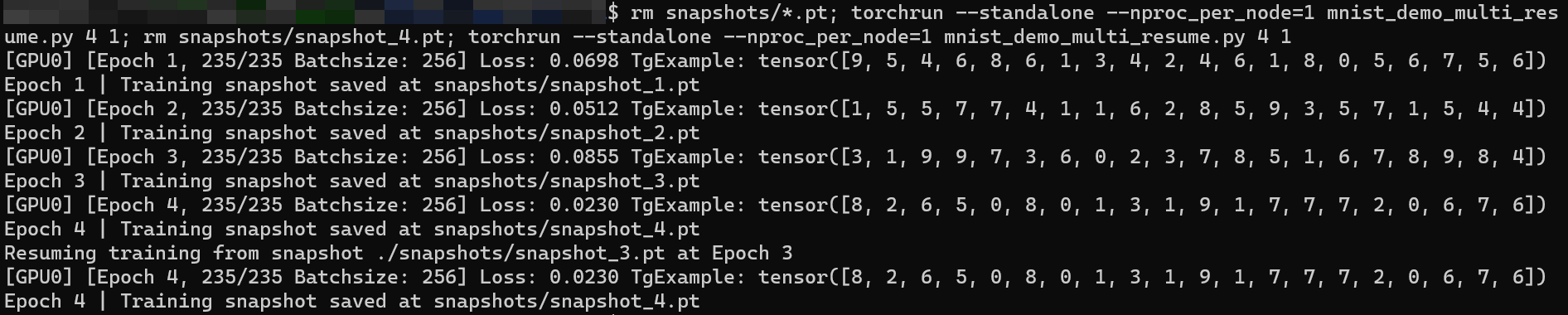
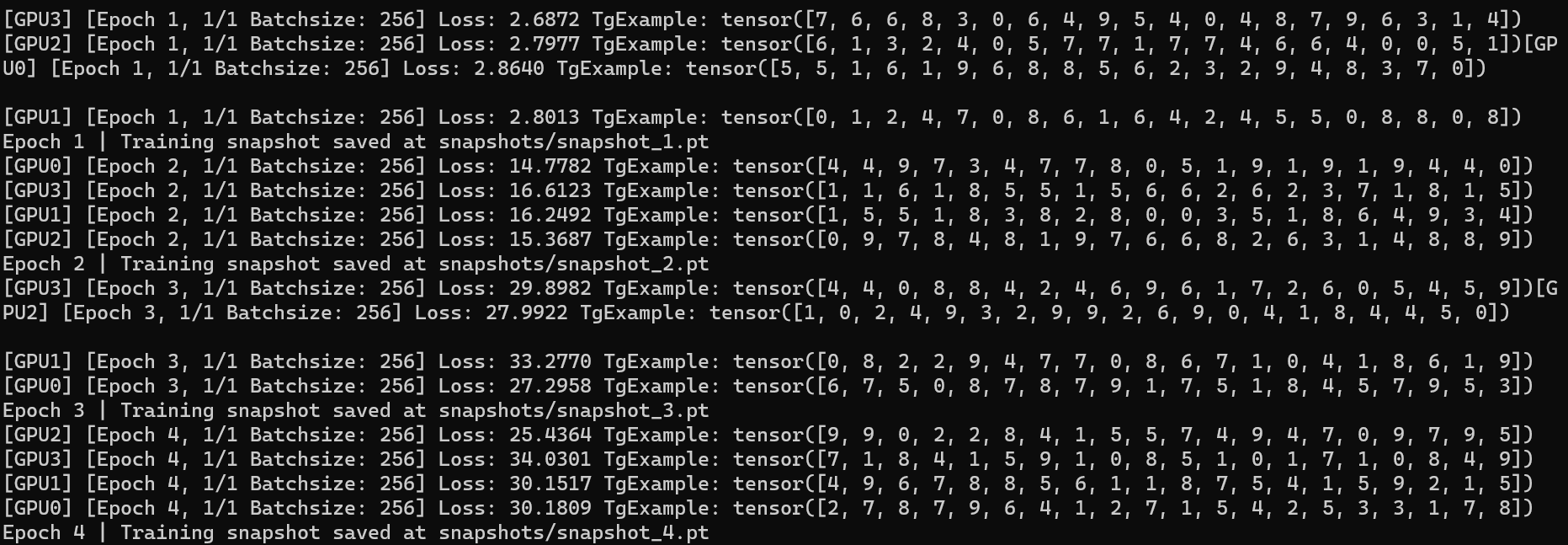
First, I repeat training of the model from scratch on multi-GPU DDP mode and can get the same training loss in each epoch iteration, which indicates that my settings do function.
run cmd torchrun --standalone --nproc_per_node=4 mnist_demo_multi_resume.py 4 1 and get (Fig. 1):
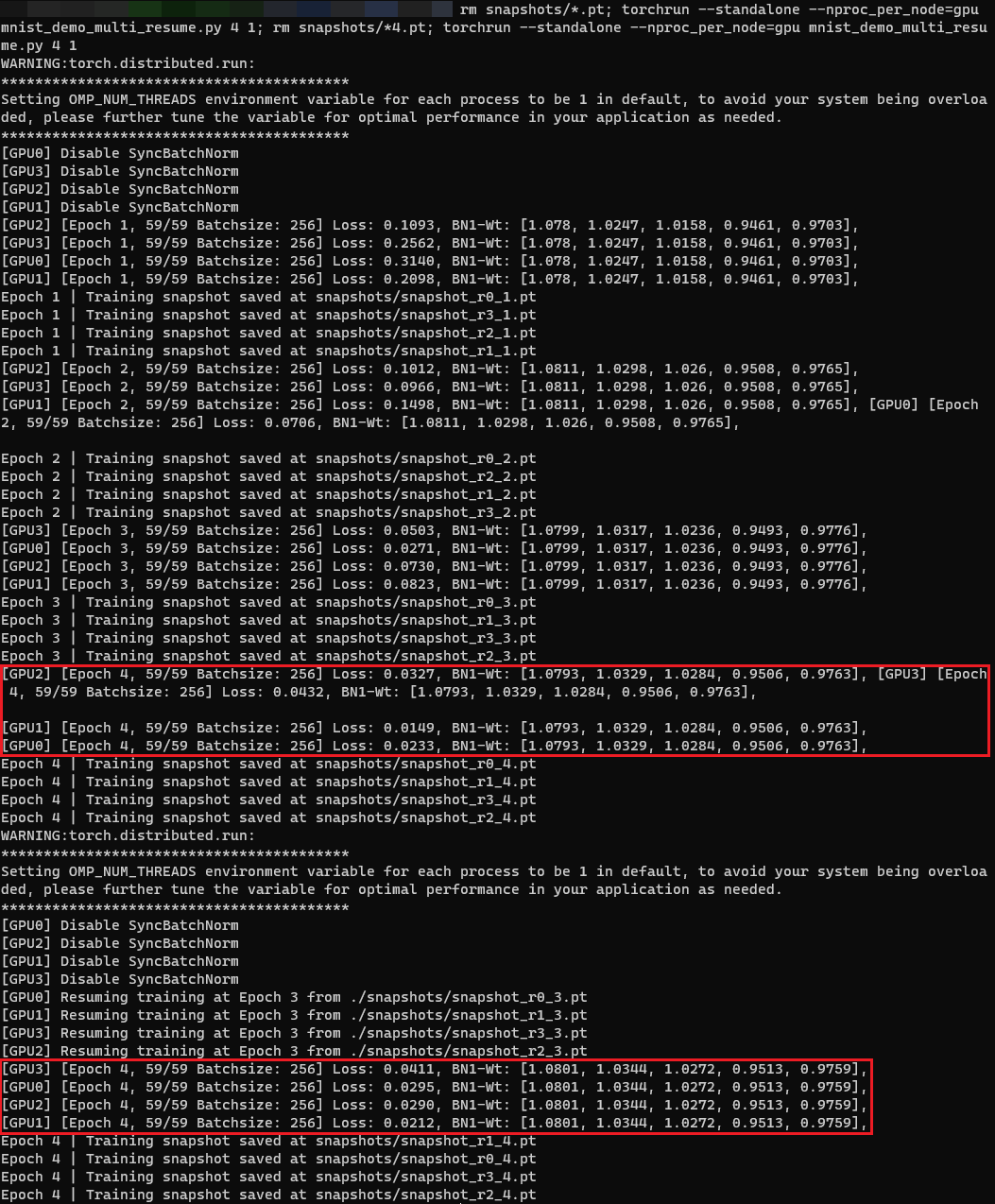
Then I delete the snapshot_4.pt, and run torchrun --standalone --nproc_per_node=4 mnist_demo_multi_resume.py 4 1 to resume training (Fig. 2):
We can see that in GPU0, the used training data label (TgExample) is same, but the loss in training from scratch mode is 0.0233 while in resuming training is 0.0295. Other losses are also different in the corresponding GPU.
But if I repeat the second operation, i.e. deleting snapshot_4.pt and resuming training, I can get the same results as shown in Fig. 2.
I am very confused about this situation and wonder what could be the reason for the above difference.
At first I suspected that the random number generator in Dataloader made trouble behind the scene. But the following test further did confuse me.
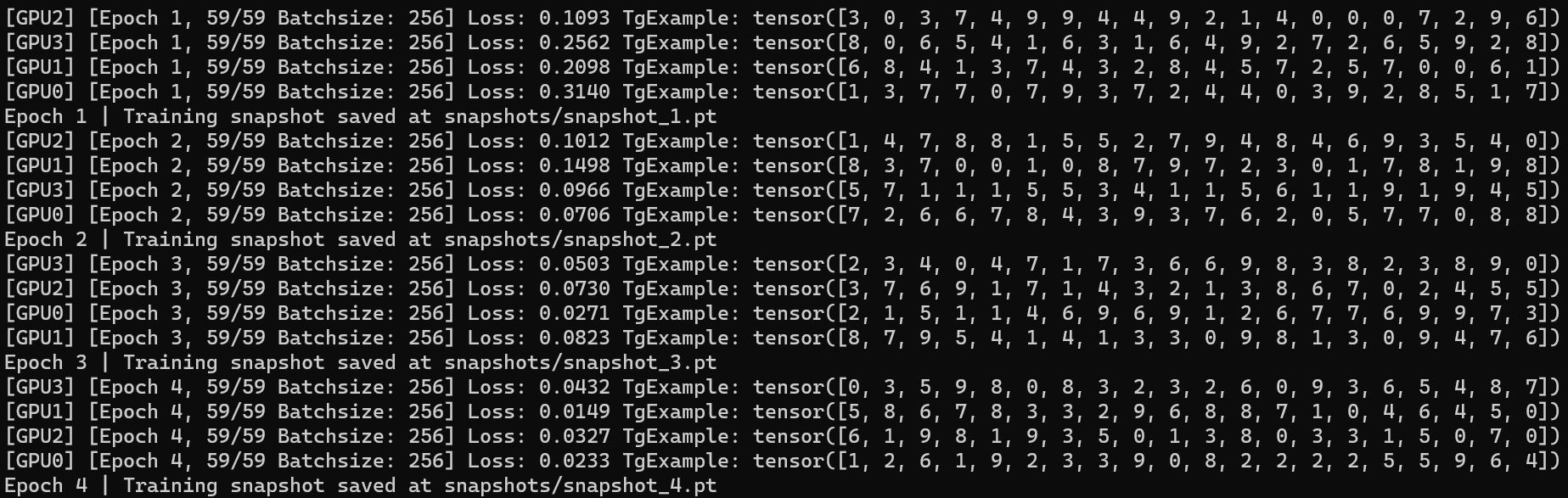
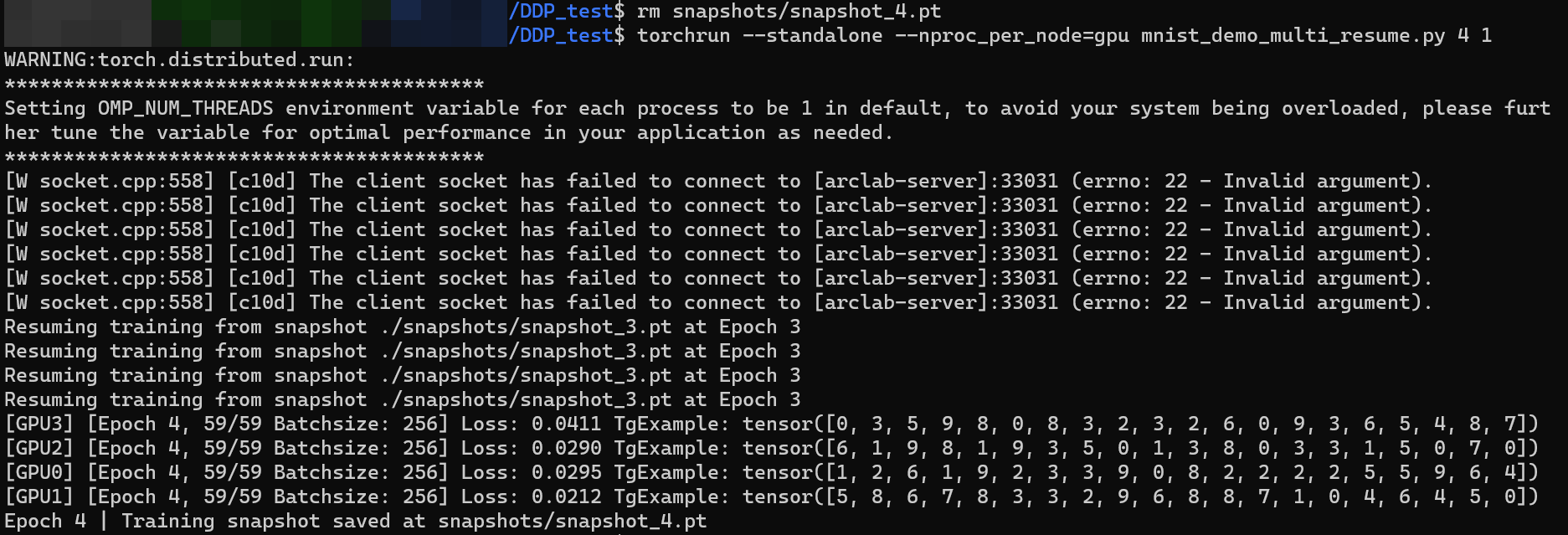
I change the number in Dataset using torch.utils.data.Subset and just use the first 1000 data for trainng, i.e. loader = prepare_dataloader(data_size=1000, batch_size=256) in my code.
Then here is the results of training from scratch (Fig. 3):
and here is the results of resuming training (Fig. 4):

As shown in Fig. 3 and Fig. 4, they produce the same results as expected.
In summary, I’m not sure what important information I’m missing that would lead to the above situation. Kindly hope someone can solve the problem.