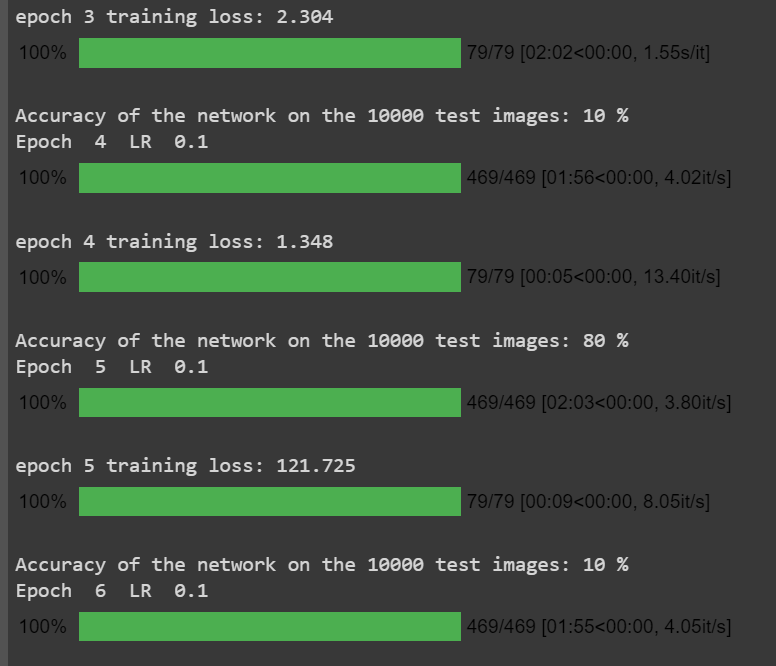
@ptrblck sir, my model is not deep. It has just 2 conv layers and 2 linear layers. The loss is not increasing, its steady at 2.303 and suddenly for just one epoch is goes to non justified value and then comes back to 2.303 in the next epoch. The model accuracy(test) though remains fixed at 10%.
Speaking of zeroing the gradients, I am doing that for each training iteration.
Attaching the training loop structure for your reference:
#training with model hyperparams
init = "normal"
for bs in batch_size:
trainloader = torch.utils.data.DataLoader(trainset, batch_size = bs, shuffle = True, num_workers = 2)
testloader = torch.utils.data.DataLoader(testset, batch_size = bs, shuffle = True, num_workers = 2)
# init_dict = best_net.state_dict()
for lr in lrs:
for momentum in momentums:
best_net.apply(init_weight_normal)
# should I try this method instead?
# best_net = Net(conv1_kernel_size=3, conv1_output_channels=24, conv2_kernel_size=5, conv2_output_channels=24, fc1_output_size=200)
# best_net.load_state_dict(init_dict)
optimizer = optim.SGD(best_net.parameters(), lr = lr, momentum = momentum)
print("Currently processing init="+init+" bs="+str(bs)+" lr="+str(lr)+" mom="+str(momentum))
# Ignore the indentation here
for epoch in range(num_epochs):
# Was trying this, but observed that zero grad is present in the train function itself
#optimizer.zero_grad()
#best_net.zero_grad()
print('Epoch ', epoch+1, ' LR ', lr)
rloss,t_accuracy = train(epoch, trainloader, optimizer, criterion, best_net)
acc_score = test(testloader, best_net)
loss_list.append(rloss)
acc_list.append(acc_score)
The train function -
def train(epoch, trainloader, optimizer, criterion, net):
running_loss = 0.0
total = 0
correct = 0
for i, data in enumerate(tqdm(trainloader), 0):
inputs, labels = data
if torch.cuda.is_available():
inputs, labels = inputs.cuda(), labels.cuda()
optimizer.zero_grad()
outputs = net(inputs)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
loss = criterion(outputs, labels)
#backward pass
loss.backward()
#weight update
optimizer.step()
running_loss += loss.item()
print('epoch %d training loss: %.3f' %(epoch + 1, running_loss/(len(trainloader))))
return [running_loss/(len(trainloader)), 100*correct/total]
And the network architecture summary -
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 16, 24, 24] 416
Conv2d-2 [-1, 16, 22, 22] 2,320
Linear-3 [-1, 1000] 7,745,000
Linear-4 [-1, 10] 10,010
================================================================
Also I just observed that for some set of configuration, the training loss is showing as ‘nan’.
I am doing something wrong wrt to the initialization. Doesn’t normal initialization work well? Or am I initializing it the wrong way?
If not what other initialization methods should I try apart from xavier-normal?