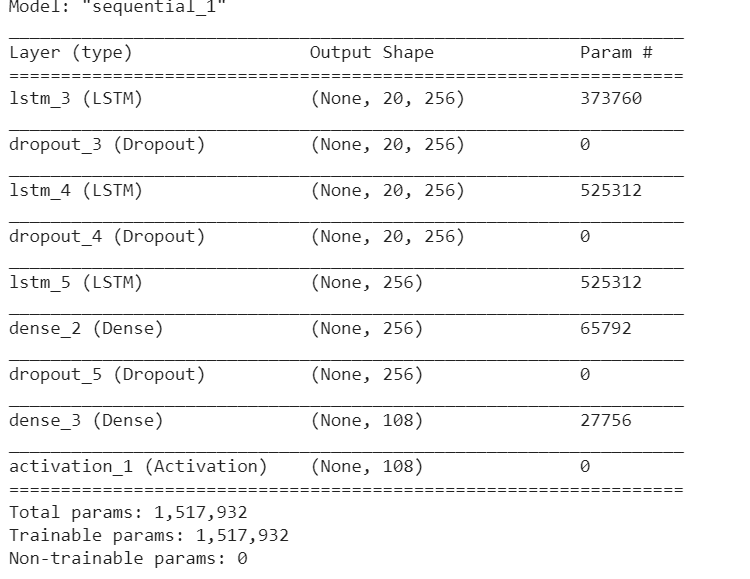
May I ask how do you go from (None, 20, 256) from layer dropout_4 to (None, 256) in lstm layer? I’m trying to rewrite this network in Pytorch but keep getting size mismatch errors. The input that I used for the keras model has shape (128, 20, 108) and the output has shape (128, 108). Input[i,:,:] is a collection of 20 one-hot-encoded vectors indicate the positions of musical notes. Output[i,:] is also one-hot-encoded vector that indicates the notes at the 21st position.
Hi! I am not some expert here but I will try to answer. The picture you have attached is for a keras model right?
Refer this stackoverflow link.
I don’t use Keras (but from reading docs), it seems that using return sequences = True will return the hidden state output for each input time step.
For this, you may use a LSTMCell maybe with a for loop to collect all the timesteps(slow I guess, somebody correct me) or you can just use the output provided by the LSTM. (See the docs for nn.LSTM)
Outputs: output, (h_n, c_n)
output of shape (seq_len, batch, num_directions * hidden_size): tensor containing the output features (h_t) from the last layer of the LSTM, for each t.
If a torch.nn.utils.rnn.PackedSequence has been given as the input,
the output will also be a packed sequence.
h_n of shape (num_layers * num_directions, batch, hidden_size): tensor containing the hidden state for t = seq_len.
c_n of shape (num_layers * num_directions, batch, hidden_size): tensor containing the cell state for t = seq_len.
So before lstm_5, it seems the keras network uses all the hidden time steps.
After that, it is only passing the latest hidden state through the network. So, you can just take the hidden state using nn.LSTM.
Also, typically people use LSTMCell in seq2seq models when they have to do some manipulation on the individual hidden states, cell states etc. Then, one feeds these to obtain the hidden,cell states for the next time step.
I have not used Keras. Is it possible that LSTM_5 is doing something beyond a simply LSTM?
As @SANKALP_SHUBHAM suggest it may simply be taking the output at the last time step.
Indeed, when looking at Keras documentation this seems to be the case
Blockquote
return_sequences: Boolean. Whether to return the last output. in the output sequence, or the full sequence. Default:False.
above from keras LSTM documentation.
if you wanted to replicate the above exactly in pytorch you could do the following either of the following:
output, hidden = yourLSTM()
1)take output[19] (your last output)
2)take hidden
The last hidden state should correspond to the last output as output simply stores the hidden states at each time step.
I am not sure that this is what you should be doing. You would be getting rid of the hidden states of all your previous timesteps. Which in this case would correspond to the previous 19 vectors.
Instead I would suggest taking the output of your LSTM of shape [1, 20,256] = [seq_len, batch_size, input_size] and reshaping it so it is of shape [20, 1, 256] = [batch_size, seq_length, input_size]. You can use torch.transpose() to do this.
Pass the reshaped data to an nn.Linear() layer with 256 neurons using your activation function of choice (2 things are same as Dense).