TorchRL Replay buffers: Pre-allocated and memory-mapped experience replay
TL;DR: We introduce a new memory-mapped storage for Replay Buffers that allows to store a large amount of data across workers and nodes, with low-latency indexing and writing.
Replay buffers are a popular feature of reinforcement learning libraries, so much so that independent packages have been dedicated to them. Getting this right of the uttermost importance to us.
We identify the following features we think researchers will be looking for in a replay buffer:
- Sampling efficiency : getting the indexes of the items to sample should be fast, even with very large buffers (=> prioritized replay buffers).
- Indexing efficiency : Indexing and returning a usable stack of elements from the replay buffer should be fast. Indexing should also be easy (e.g.
storage[idx]or similar). - Storage modularity : it should be possible to easily choose where to store the elements stored in the buffer, e.g. in memory, on disk, perhaps on cuda etc.
- Sampling modularity : integrating new samplers should be doable with little effort.
- Distributed access : it should be possible for multiple workers/nodes to access a common replay buffer and write items into it.
As we prepare for a beta release of the library, we thought that it would be important to stabilize the replay buffer API as we can still introduce bc-breaking changes in the library. Once we’ll be at the beta stage and after, our API should be stable enough such that users can rely on it without worrying about upcoming upgrades. Hence, we are doing our best to tick all the above-mentioned boxes as soon as can be.
Regarding sampling efficiency , we have been blessed with the rlmeta c++ implementation of a SegmentTree structure that makes sampling easy and efficient in prioritized settings. The ReplayBuffer class associated with is also has some great features, such as multi-threaded sampling etc.
As of now, we have one dedicated replay-buffer class per sampling strategy . This means that adding a new sampler will require implementing a new RB class, which may be suboptimal as a great deal of the existing features will remains identical. We are contemplating the idea of making our replay buffer more similar to Reverb’s ones (and, for what it’s worth, to the Dataloader(dataset, sampler, collate_fn) API, except that adding elements to the buffer must be implemented as well). This would make the buffer class behave as
buffer = ReplayBuffer(sampler=sampler, storage=storage, collate_fn=collate_fn)
and in the future a remover can be added as well (feel free to upvode that feature if you feel it is of the uttermost importance to get this fast!)
Storage and indexing
Storage and indexing are trickier to get right: until now, our storage simply consisted in adding items one at a time in a list, from which items were indexed and stacked using an ad-hoc collate_fn . This has the notable advantage of being robust to samples of different sizes or dtypes (e.g. truncated trajectories etc), as the assumptions about the data coming in was minimal. However, it requires us to index a list and then process the collected items accordingly, which is suboptimal. The other inconvenient with this approach is that it can be hard to foresee what will be the memory requirement of the buffer: if images or videos are collected, it may very well happen that the training script will be interrupted after some time due to an out-of-memory issue, even more so if the collected items have a variable size.

To solve these issues, we introduce a new storage class, LazyMemmapStorage , which stores tensors on disk using a tensor-like class (MemmapTensor ) that is an interface between np.memmap and torch.Tensor . np.memmap has significant advantages: first, it is easy to specify where the data should be stored. In many cases, the scratch space location is tailored to the infra and cluster requirements, making a default /tmp/file location unsuited. Second, indexing from np.memmap is easy and efficient: those arrays can be accessed at multiple different indices without much overhead. Third, the upper limit of MemmapTensors opened at the same time is looser than the number of shared-memory tensors for instance. Finally, storing these data on disk rather than memory makes it easy to retrieve data after a job failure. However, MemmapTensors do not support differentiation, but this is an unusual feature for tensors stored in a replay buffer anyway.
The API can now be sketched in the following way (for a single tensor):
buffer = ReplayBuffer(
cfg.buffer_size,
collate_fn=lambda tensors: tensors,
storage=LazyMemmapStorage(cfg.buffer_size)
)
As the name indicates, the storage is lazy in the sense that it will be populated once it reads the first tensor that it is given.
>>> buffer.add(torch.randn(3)) # `add` adds a single element to the buffer
Creating a MemmapStorage...
The storage was created in /tmp/tmpz_3dpje2 and occupies 0.00011444091796875 Mb of storage.
>>> buffer.sample(1).shape
torch.Size([1, 3])
>>> buffer._storage[2] # not assigned yet
torch.tensor([0., 0., 0.])
This allows for easy-to-generalize buffer initialization across algorithms and environments. In our implementation, indexing strategy is the responsibility of the storage class: unlike the regular ListStorage , LazyMemmapStorage will not access the indexed items one at a time and stack them using collate_fn . Instead, it will create a stack of indices such that the memory-mapped array is indexed only once. In practice, this brings a speed-up of one or two orders of magnitude.
Of course, usually replay buffers need not to store one tensor category but a lot more of them. For these cases, TorchRL provides a TensorDict class that casts common operations such as reshaping, moving to device and indexing across tensors stored in a dictionary. Of course, LazyMemmapStorage supports TensorDict s inputs seamlessly:
>>> td = TensorDict({"a": torch.randn(10, 3), "b": torch.ones(10, 1)}, batch_size=[10])
>>> storage = LazyMemmapStorage(10, scratch_dir="/scatch/")
>>> buffer = ReplayBuffer(
... 10,
... collate_fn=lambda x: x, # we don't need to do anything, TensorDict will do it for us
... storage=storage)
>>> buffer.extend(td) # `extend` adds multiple elements to the buffer (unlike `add`)
Creating a MemmapStorage...
The storage is being created:
a: /tmp/tmp1m7m9uig, 0.00011444091796875 Mb of storage (size: [10, 3]).
b: /tmp/tmpsilpr0kg, 3.814697265625e-05 Mb of storage (size: [10, 1]).
>>> sample = buffer.sample(3)
>>> sample
SubTensorDict(
fields={
a: MemmapTensor(torch.Size([3, 3]), dtype=torch.float32),
b: MemmapTensor(torch.Size([3, 1]), dtype=torch.float32)},
batch_size=torch.Size([3]),
device=cpu,
is_shared=False)
>>> sample.get("b")
tensor([[1.],
[1.],
[1.]])
Again, the collate function is the identity as the only thing we need to do to gather a stack of samples is to index the corresponding tensordict (under the hood, the only operation that LazyMemmapStorage does is out_tensordict = self.memmap_tensordict[idx] ).
Performance
We tested the replay buffer sampling speed across 3 types of storage (list, pre-allocated tensors, pre-allocated memory-mapped tensors), and across 3 types of data input (simple 3 x 4 floating point tensors, dictionary of tensors, and corresponding TensorDict). The test consisted in populating a RB with 100K examples and sampling from it batches of 128 elements. The test file can be found attached to this note. The complexity of storing and indexing simple tensors (left group on the figure) is obviously lower as there is only a single data source. Storing dictionaries (middle group) was only tested using the regular ListStorage as dictionaries cannot be indexed (unlike TensorDicts ): in other words, improving dictionaries to make them indexable and using them with LazyTensorStorage and LazyMemmapStorage is the purpose of the TensorDict class.
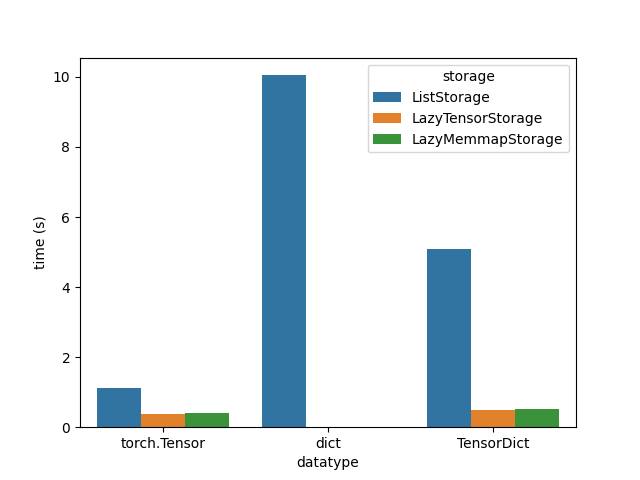
We can observe that sampling a stored, single, pre-allocated tensor (right group, either in memory – orange – or on disk – green) is much faster than sampling from a list and stacking elements together (right group, blue): in other words, Memmap and pre-allocated tensors are faster than lists as expected. Also, the overhead of storing items on disk is negligeable but this depends on the storage specs. Nevertheless, notice that TensorDict does a decent job with the ListStorage already compared to the naive dictionaries (middle vs right blue bar) ![]() .
.
Finally, regarding the distributed side of things, LazyMemmapStorage paves the way to shared storages across can be placed anywhere on the available partitions: if nodes have access to a common space with reasonably fast common storage, they will all be capable of writing items to the buffer and access it at low cost. Stay tuned to hear more about this!