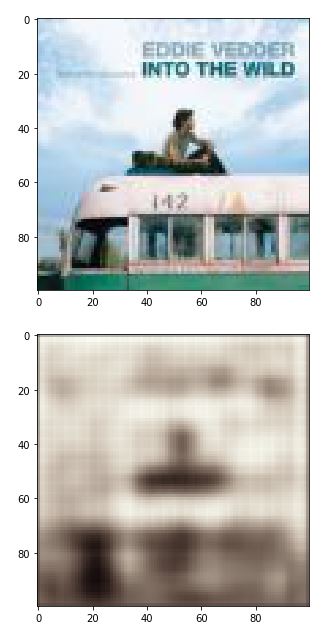
Thank you for the answer @ptrblck. I have been checking matplotlib and other tools and it is still showing me the same image. It must be due to the model. I have also tried to change some hyperparameters but it is still not working. This is the convolutional autoencoder I am using:
class Autoencoder (nn.Module):
def __init__(self, en_out1=32, en_out2=64, en_out3=64, en_out4=64, dec_out1=64, dec_out2=64, dec_out3=32):
super(Autoencoder, self).__init__()
#Encoder parameters
self.en_conv1 = nn.Conv2d(in_channels=3, out_channels=en_out1, kernel_size=3, padding=1)
self.bn1 = nn.BatchNorm2d(en_out1)
self.en_conv2 = nn.Conv2d(in_channels=en_out1, out_channels=en_out2, kernel_size=3, stride=2, padding=1)
self.bn2 = nn.BatchNorm2d(en_out2)
self.en_conv3 = nn.Conv2d(in_channels=en_out2, out_channels=en_out3, kernel_size=3, stride=2, padding=1)
self.bn3 = nn.BatchNorm2d(en_out3)
self.en_conv4 = nn.Conv2d(in_channels=en_out3, out_channels=en_out4, kernel_size=3, padding=1)
self.bn4 = nn.BatchNorm2d(en_out4)
self.lin1 = nn.Linear(en_out4 * 25 * 25, 200)
# Decoder parameters
self.lin2 = nn.Linear(200, en_out4 * 25 * 25)
self.dec_conv1 = nn.ConvTranspose2d(in_channels=en_out4, out_channels=dec_out1, kernel_size=3, padding=1)
self.bn5 = nn.BatchNorm2d(dec_out1)
self.dec_conv2 = nn.ConvTranspose2d(in_channels=dec_out1, out_channels=dec_out2, kernel_size=3, stride=2, padding=1, output_padding=1)
self.bn6 = nn.BatchNorm2d(dec_out2)
self.dec_conv3 = nn.ConvTranspose2d(in_channels=dec_out2, out_channels=dec_out3, kernel_size=3, stride=2, padding=1,
output_padding=1)
self.bn7 = nn.BatchNorm2d(dec_out3)
self.dec_conv4 = nn.ConvTranspose2d(in_channels=dec_out3, out_channels=3, kernel_size=3, padding=1)
self.dropout = nn.Dropout(0.25)
self.leakyrelu = nn.LeakyReLU(0.01)
def encoder(self, x):
x = self.dropout(self.bn1(self.leakyrelu(self.en_conv1(x))))
x = self.dropout(self.bn2(self.leakyrelu(self.en_conv2(x))))
x = self.dropout(self.bn3(self.leakyrelu(self.en_conv3(x))))
x = self.dropout(self.bn4(self.leakyrelu(self.en_conv4(x))))
x = x.view(x.size(0), -1)
latent_space = self.lin1(x)
return latent_space
def decoder(self, latent_space):
x = self.lin2(latent_space)
x = x.view(x.size(0), 64, 25, 25)
x = self.dropout(self.bn5(self.leakyrelu(self.dec_conv1(x))))
x = self.dropout(self.bn6(self.leakyrelu(self.dec_conv2(x))))
x = self.dropout(self.bn7(self.leakyrelu(self.dec_conv3(x))))
x = self.dec_conv4(x)
x = torch.sigmoid(x)
return x
def forward(self, x):
latent_space = self.encoder(x)
x_ = self.decoder(latent_space)
return x_
Model intialization, criterion and optimizer:
# ----------------------------------------------- DEFINE MODEL --------------------------------------------------------#
torch.manual_seed(42)
device = torch.device('cuda')
model = Autoencoder(en_out1=32, en_out2=64, en_out3=64, en_out4=64, dec_out1=64, dec_out2=64, dec_out3=32)
model.cuda(device)
# ------------------------------------------- CRITERION & OPTIMIZER ---------------------------------------------------#
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=5e-4, betas=(.9, .99), weight_decay=1e-2)
And training:
# ------------------------------------------------ TRAINING ----------------------------------------------------------#
torch.set_grad_enabled(True)
n_epochs = 20
cost_list = []
COST = 0
for epoch in tqdm.tqdm(range(n_epochs)):
COST = 0
if epoch == 10:
optimizer = torch.optim.Adam(model.parameters(), lr=2e-4, betas=(.9, .99), weight_decay=1e-2)
for i, data in enumerate(train_loader):
img, _ = data
img = img.to(device)
optimizer.zero_grad()
z = model.forward(img)
loss = criterion(z,img)
loss.backward()
optimizer.step()
COST += loss.data
if i % 50 == 0:
print(loss)
cost_list.append(COST)
torch.save(model.state_dict(), 'model.pth')
Am I missing something?
Thank you in advance