Hey there, I am having some problems with a Video Detection RNN. My Architecture looks like the following:
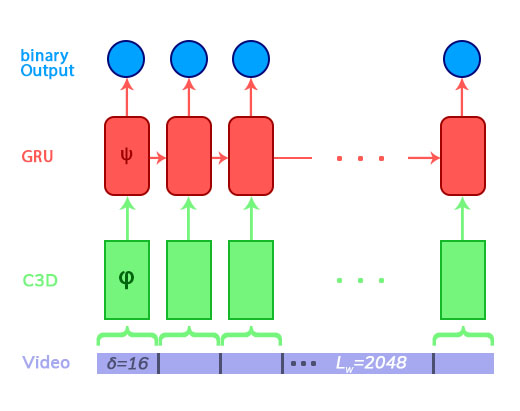
For training, I am having a video with vid_length=2048 frames, I divide the the video into vid_length / delta separate blocks. These blocks are used as input for a (3D-ConvNet) C3D-feature-extractor so this Conv3d net is encoding the features from delta=16 frames. I then flatten the output and use it as input for GRU layer this outputs a value between 0 - 1 which is the classification for the the delta=16 frames at time_step=n (where n is from 1 to vid_lenght / delta.
Now to my question: My seq_length=512 frames ergo feature_seq_length=32 so the input for the GRU is of size (batch, 32, C3D_output_size) . How do I process the input for the C3D so I that I have the 32 outputs as inputs for the GRU. I would like that the model is trainable end-to-end? My approach would be to run the C3D on the 512 frames to get 32 outputs and use those as a sequence for the GRU. What is your opinion on this?


 , the dataset part is really helpful, WOW! <3<3<3 Gonna implement it further and will let you know!
, the dataset part is really helpful, WOW! <3<3<3 Gonna implement it further and will let you know!