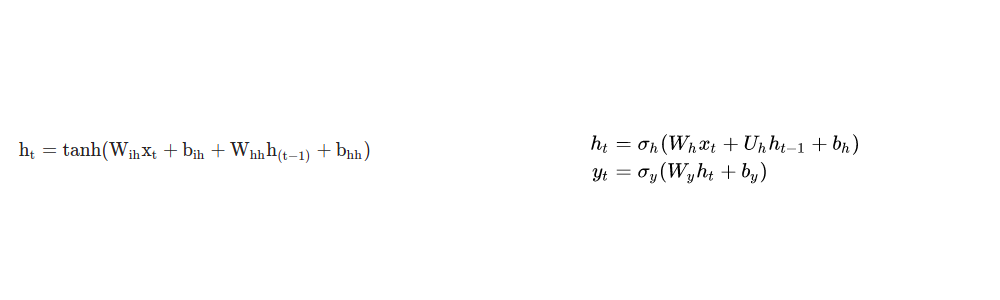On the left side Pytorch official implementation.
On the right side I took formulas for Wikipedia and A.Karpathy article.
Both of the formulas claims that they are Elman implementations. But in Wikipedia and A.Karpathy article they have 3 set of weights W_i, W_h, W_y when in Pytorch implementation only 2 set of weights.
The third weight is for the output vector. When RNNs have both outputs and hidden states that are output, there will be a third weight matrix for the y output. That third weight matrix is W_y. The PyTorch doc is specifically for the hidden activation function, which only has two weights in the equation.
On the left, PyTorch docs specify the tanh activation function, while the right equation has a generic activation function.
The right-hand side equation also has only one bias.