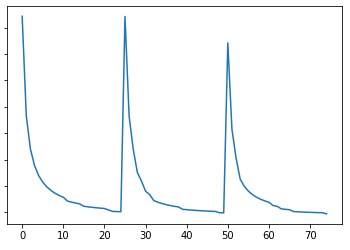
I’ve been working on a simple RNN model to predict the next word, I manage to make the model but for some reason is it not learning (the loss is roughly the same at every iteration). Anyone can spot some bug in my code?
class RNN(nn.Module):
def init(self, input_size, hidden_size, output_size):
super(RNN, self).init()
self.hidden_size = hidden_size
self.x2h = nn.Linear(input_size, hidden_size)
self.h2h = nn.Linear(hidden_size, hidden_size)
self.h2o = nn.Linear(hidden_size, output_size)
self.softmax = nn.Softmax(dim=1)
def forward(self, input, hidden):
hidden1 = self.x2h(input)
hidden2 = self.h2h(hidden)
hidden = hidden1 + hidden2
output = self.h2o(hidden)
output = self.softmax(output)
return output, hidden
def initHidden(self):
return torch.zeros(1, self.hidden_size)
rnn_1 = RNN(n_vocab, n_hidden, n_vocab)
optimizer_1 = torch.optim.Adam(rnn_1.parameters(), lr=learning_rate)
criterion = nn.CrossEntropyLoss()
def train(text_x_tensor,label): #text_x_tensor = [4,1,2721]
hidden = rnn.initHidden()
rnn_1.zero_grad()
for tensor in text_x_tensor: #Loop over the 4 context words
output_1, hidden_1 = rnn_1(tensor, hidden_1) #output_1 = [1,2721]
loss = criterion(output_1,label)
loss.backward()
optimizer_1.step()
return output_1,loss.item(), hidden_1
n_epochs = 3
for epoch in range(n_epochs):
#Shuffle batches
random.shuffle(batches)
for i,batch in enumerate(batches):
output_1, loss, hidden_1 = train(batch[0], batch[1])