I am working on a text classification problem with a binary output of 0 or 1. I am rather new to both NLP and Pytorch. I am just trying to build a simple RNN model character level. But the losses don’t seem to even overfit.
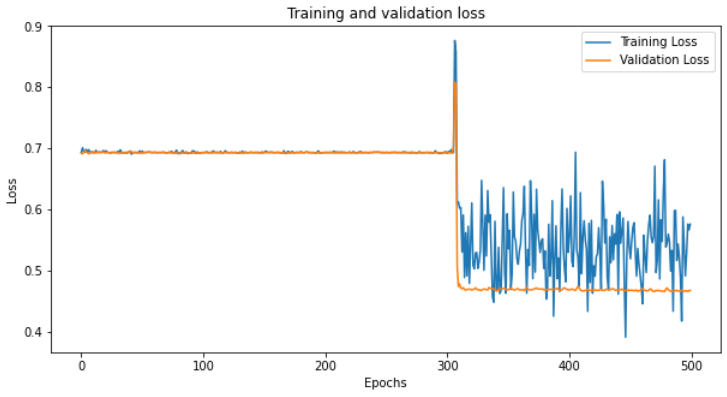
My problem is that the accuracy, train loss and test loss remain the same during all epochs.
I tried to increase the number of epochs though, and the results are strange. The model’s loss only sometimes improves after 300 epochs and then starts to fluctuate, but mostly it just settles on the loss it started with the beginning (meaning that it doesn’t improve (the numbers change slightly though but fluctuating). When the loss decreases after 300 epochs, the test accuracy is about 90%.
I have tried adding an activation function, gradient clipping, change to GRU or LSTM, but the same problem exists!
class TagsRNN(nn.Module):
"""
The RNN model that will be used to perform classification.
I think seq_len should be 100 (number of words in a sentence)
"""
def __init__(self, input_size, hidden_dim, n_layers, output_size):
"""
Initialize the model by setting up the layers
"""
super().__init__()
self.output_size=output_size
self.n_layers=n_layers
self.hidden_dim=hidden_dim
self.input_size=input_size
#Embedding and LSTM layers
# self.embedding=nn.Embedding(vocab_size, embedding_dim)
self.rnn=nn.RNN(input_size, hidden_dim, n_layers, batch_first=True)
self.fc = nn.Linear(hidden_dim, output_size)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
"""
Perform a forward pass of our model on some input and hidden state.
"""
h0 = torch.zeros(self.n_layers, x.size(0), self.hidden_dim).to(device)
out, _ = self.rnn(x, h0)
# out: batch_size, seq_len, hidden_dim
out = out[:, -1, :] # to get the last thing in the sequence (to follw the architecture's many-to-one)
out = self.fc(out)
# out: batch_size, hidden_dim
# out: batch_size, output_size
out = self.sigmoid(out)
return out
sequence_length
input_size = len(all_letters) + 2 # +2 for padding and unknown
n_layers = 5
hidden_size = 100
output_nodes = 1
modelRNN = TagsRNN(input_size,hidden_size, n_layers, output_nodes).to(device)
def train(train_loader, val_loader, model, criterion, optimizer, n_epochs):
all_train_losses = []
all_val_losses = []
for epoch in range(n_epochs):
train_losses = []
val_losses = []
for i, (x, labels) in enumerate(train_loader):
# shape of x: (batch_size, seq_len) => (N, 100)
# resize it to (batch_size, seq_len, input_size) => (N, 100, 65)
x = F.one_hot(x, num_classes=input_size).type(torch.FloatTensor).to(device)
labels = labels.to(device)
# Forward pass
outputs = model(x)
loss = criterion(outputs.squeeze(), labels.type(torch.FloatTensor).to(device))
# backward and optimize
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch+1) % 10 == 0:
print ('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'
.format(epoch+1, num_epochs, i+1, len(train_loader), loss.item()), end=' ')
train_losses.append(loss.item())
# validate
with torch.no_grad():
for i, (x, labels) in enumerate(val_loader):
# shape of x: (batch_size, seq_len) => (N, 100)
# resize it to (batch_size, seq_len, input_size) => (N, 100, 65)
x = F.one_hot(x, num_classes=input_size).type(torch.FloatTensor).to(device)
labels = labels.to(device)
# Forward pass
outputs = model(x)
loss = criterion(outputs.squeeze(), labels.type(torch.FloatTensor).to(device))
val_losses.append(loss.item())
if (epoch+1) % 10 == 0:
print(',Val Loss: {:.4f}'.format(np.mean(val_losses)))
all_val_losses.append(np.mean(val_losses))
all_train_losses.append(np.mean(train_losses))
return all_train_losses, all_val_losses
batch_size = 64
learning_rate = 0.001
num_epochs = 500
criterion = nn.BCELoss()
optimizer = torch.optim.Adam(modelRNN.parameters(), lr=learning_rate)
all_train_losses, all_val_losses = train(train_loader, val_loader, modelRNN, criterion, optimizer, num_epochs)